Point clé
L'ARC approuve les réclamations RS&DE en IA/ML lorsque vous prouvez que les méthodes connues ont échoué, documentez une investigation structurée et démontrez les nouvelles connaissances produites.
Chaque entreprise logicielle qui construit avec l’IA se pose la même question au moment des impôts : est-ce que notre travail est admissible à la RS&DE?
L’ARC a remarqué la tendance. Les réclamations liées à l’IA/ML ont augmenté d’environ 40 % par année depuis 2023. En réponse, les conseillers scientifiques de l’ARC ont affiné leurs critères d’évaluation. Des documents d’orientation internes diffusés au début de 2026 traitent spécifiquement de l’évaluation des réclamations en apprentissage automatique. Le principe n’a pas changé. Mais la façon dont les évaluateurs l’appliquent au travail en IA/ML est plus précise, et moins indulgente envers les réclamations vagues.
Cet article couvre la ligne d’admissibilité pour les catégories les plus courantes de travail en IA/ML : curation de données d’entraînement, prompt engineering, ajustement de modèles, développement d’architectures novatrices et MLOps.
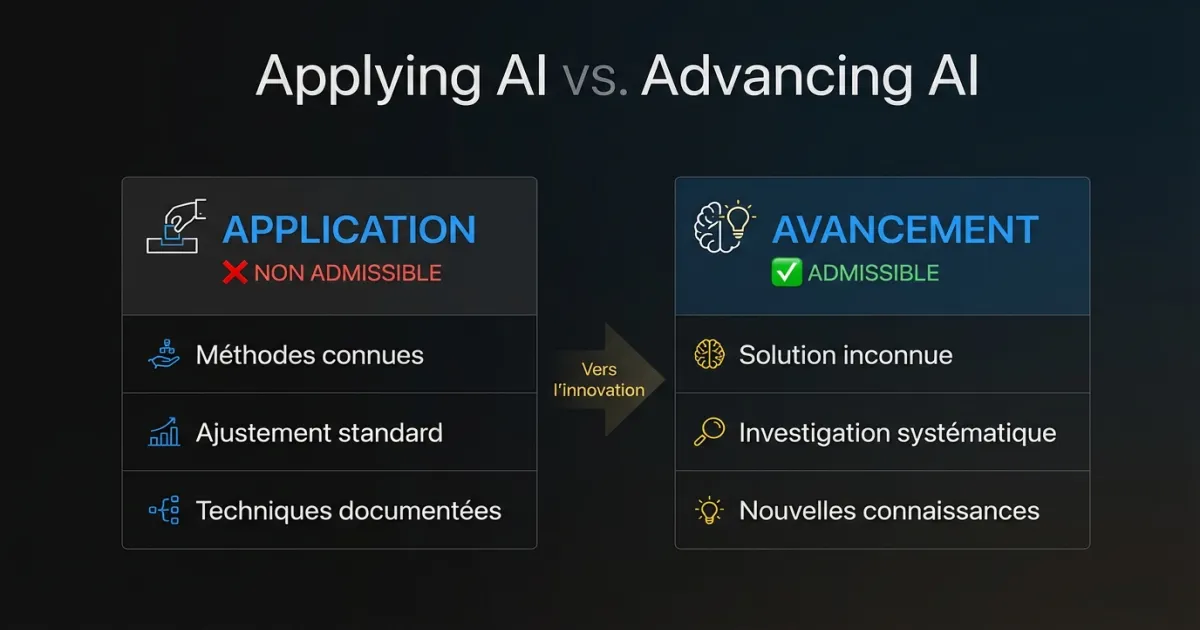
Quelle est la différence entre « utiliser l’IA » et « faire avancer l’IA »?
Le test d’admissibilité en trois volets de l’ARC s’applique à l’IA/ML comme à toute autre technologie. Le travail doit impliquer une incertitude technologique, une investigation systématique et un avancement technologique.
Le problème : la plupart du travail en IA/ML dans les entreprises logicielles relève de l’application, pas de l’avancement. Votre équipe a ajusté un modèle de langage pour extraire des clauses contractuelles. C’est de l’ingénierie impressionnante. Mais à moins que le processus d’ajustement lui-même ait nécessité de résoudre un problème non adressable par les techniques connues, c’est de l’application de la technologie existante.
Les évaluateurs de l’ARC distinguent maintenant clairement deux catégories.
Application de l’IA/ML signifie utiliser des modèles, techniques et flux de travail établis pour résoudre un problème d’affaires. Entraîner un classificateur sur des données étiquetées avec des architectures standards. Ajuster un LLM avec des méthodes bien documentées. Déployer un modèle avec des pipelines MLOps standards. Rien de cela ne se qualifie seul.
Avancement de l’IA/ML signifie rencontrer un problème technique où les méthodes connues étaient insuffisantes, investiguer des approches alternatives de manière systématique et produire de nouvelles connaissances sur ce qui fonctionne et pourquoi. Cela peut se qualifier.
La distinction ne porte pas sur la difficulté du travail. Elle porte sur le fait que la solution était connaissable avant de commencer.
Est-ce que la curation de données d’entraînement est admissible à la RS&DE?
Rarement seule. L’orientation mise à jour de l’ARC est directe : collecter, nettoyer, étiqueter et organiser des données d’entraînement n’est pas un travail admissible, sauf si le processus de curation lui-même a nécessité de résoudre une incertitude technologique.
Ce qui ne se qualifie pas
- Construire un pipeline de données pour ingérer et normaliser des documents de sources multiples
- Étiquetage manuel ou semi-automatisé d’exemples d’entraînement
- Techniques standard d’augmentation de données (rotation, recadrage, remplacement de synonymes)
- Rédaction de règles de validation pour filtrer les échantillons de faible qualité
Tout cela est de la pratique courante. Un ingénieur de données compétent appliquant des méthodes connues peut l’exécuter.
Ce qui peut se qualifier
- Développer une approche novatrice d’apprentissage actif parce que les budgets d’étiquetage ne pouvaient pas supporter le volume requis, et les méthodes existantes produisaient un biais de sélection inacceptable pour votre distribution de données
- Investiguer si la génération de données synthétiques pouvait remplacer des échantillons réels dans un domaine où aucune recherche antérieure n’existait sur le transfert synthétique-à-réel
- Créer une nouvelle méthodologie de débiaisement où les techniques standards (rééchantillonnage, repondération) échouaient à traiter les patrons de biais intersectionnels spécifiques à votre domaine
Le facteur qualifiant est toujours le même : une technique connue était insuffisante, votre équipe a investigué des alternatives par expérimentation structurée, et l’investigation a produit des connaissances qui n’existaient pas auparavant.
Est-ce que le prompt engineering est admissible à la RS&DE?
Presque jamais. Cette catégorie attire le plus de rejets de l’ARC en 2026.
Rédiger des prompts, tester des variations, évaluer les sorties et itérer sur la formulation est un processus d’optimisation utilisant un outil connu. Le comportement du LLM est la technologie du fournisseur. Trouver comment obtenir de meilleurs résultats est de l’application, pas de la recherche.
Ce qui ne se qualifie pas
- Itérer sur des prompts système pour améliorer la précision des réponses
- Développer des modèles de prompts pour des cas d’utilisation spécifiques
- Tester les approches chaîne de pensée vs. few-shot pour une tâche particulière
- Construire des cadres d’évaluation pour noter l’efficacité des prompts
L’exception étroite
Le prompt engineering peut contribuer à une réclamation admissible lorsqu’il fait partie d’une investigation plus large sur une véritable incertitude technologique. Exemple : votre équipe recherche si les LLM peuvent effectuer un raisonnement causal fiable dans un domaine technique spécifique, et les variations de prompts sont une variable expérimentale parmi plusieurs (architecture du modèle, approche d’ajustement, stratégie de récupération). Le travail sur les prompts soutient l’investigation. Il n’est pas l’investigation elle-même.
Même dans ce cas, les heures de prompt engineering seules ne se qualifient pas. C’est du travail de soutien dans un projet admissible plus large.
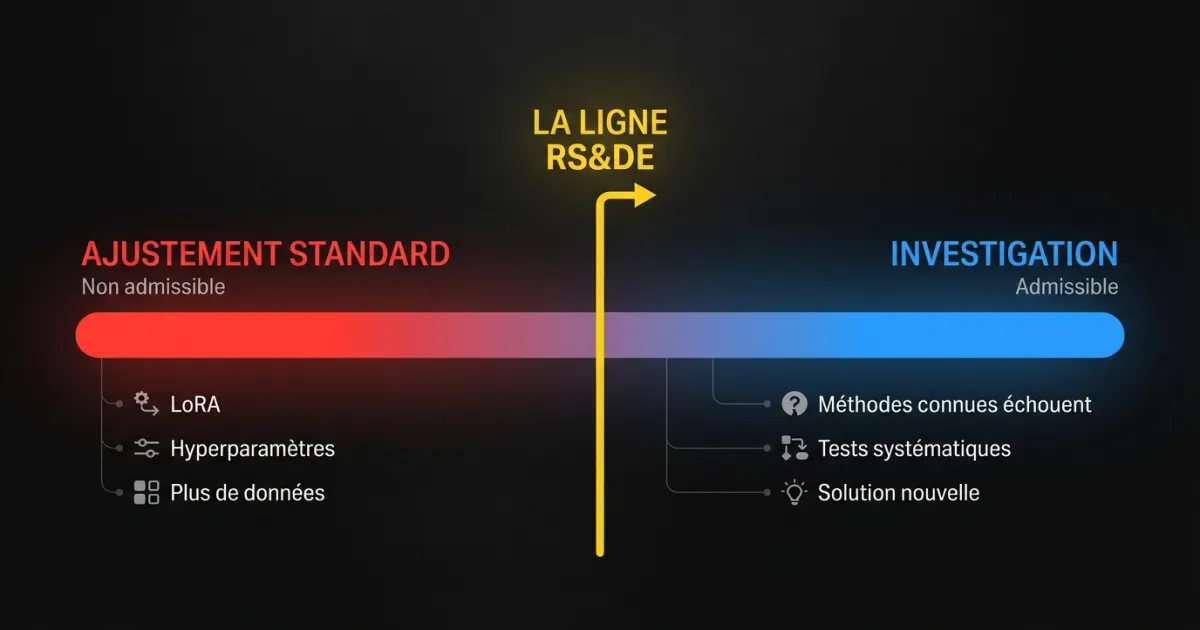
Quand l’ajustement de modèle entre-t-il en territoire RS&DE?
L’ajustement est la zone grise où la plupart des disputes RS&DE en IA/ML surviennent. La position de l’ARC est devenue plus nuancée en 2026.
Ajustement standard : ne se qualifie pas
Prendre un modèle pré-entraîné, préparer un jeu de données spécifique au domaine et ajuster avec des méthodes établies (LoRA, QLoRA, ajustement supervisé standard) est de l’ingénierie appliquée. Les techniques sont documentées. Le processus est bien compris. Un ingénieur ML qualifié suivant des guides publiés peut l’exécuter.
C’est vrai même si les résultats sont impressionnants. L’ARC n’évalue pas si la sortie est précieuse. Elle évalue si le processus a nécessité de résoudre une inconnue.
Ajustement qui se qualifie
Le travail entre en territoire RS&DE lorsque les approches standards échouent et que votre équipe doit investiguer pourquoi.
Exemple admissible : Votre équipe a ajusté un modèle de 7 milliards de paramètres pour la classification de documents médicaux. L’ajustement LoRA standard a atteint 72 % de précision, bien en dessous du seuil clinique de 95 %. Votre équipe a émis l’hypothèse que l’échec provenait de l’incapacité du modèle à maintenir le contexte à travers des documents de plusieurs pages. Vous avez systématiquement testé cinq approches : fenêtrage d’attention modifié, découpage hiérarchique avec attention inter-segments, un pipeline récupération-puis-classification en deux étapes, des modifications d’encodage positionnel personnalisées et un ensemble de sous-modèles spécialisés. Trois approches ont échoué. La quatrième a dégradé la performance sur les documents courts. La cinquième, nécessitant une combinaison novatrice de découpage hiérarchique avec attention croisée personnalisée non décrite dans la littérature existante, a atteint 96 %. Chaque expérience a été documentée avec hypothèses, configurations, résultats et raisonnement technique.
Cela se qualifie. L’incertitude technologique était réelle. L’investigation était systématique. Le résultat a fait avancer l’état de l’art pour cette classe de problèmes.
Exemple non admissible : Votre équipe a ajusté le même modèle pour la classification de tickets de support. L’ajustement LoRA standard a atteint 89 %. Vous vouliez 93 %. Vous avez essayé l’ajustement d’hyperparamètres, ajouté plus de données d’entraînement et modifié les calendriers de taux d’apprentissage. Après plusieurs itérations, vous avez atteint 92,5 %.
C’est de l’optimisation, pas de la recherche. Les techniques étaient standards. L’incertitude portait sur le degré de performance, pas sur la viabilité de l’approche.
Travail sur des architectures novatrices
Construire des architectures de modèles véritablement nouvelles se qualifie presque toujours, car par définition vous créez quelque chose d’absent de la littérature publiée. Mais les évaluateurs de l’ARC vérifieront que la nouveauté est réelle. Si votre « architecture novatrice » est un transformer standard avec une tête d’attention modifiée, ils vérifieront si cette modification spécifique était déjà décrite dans des articles ou des implémentations open source.
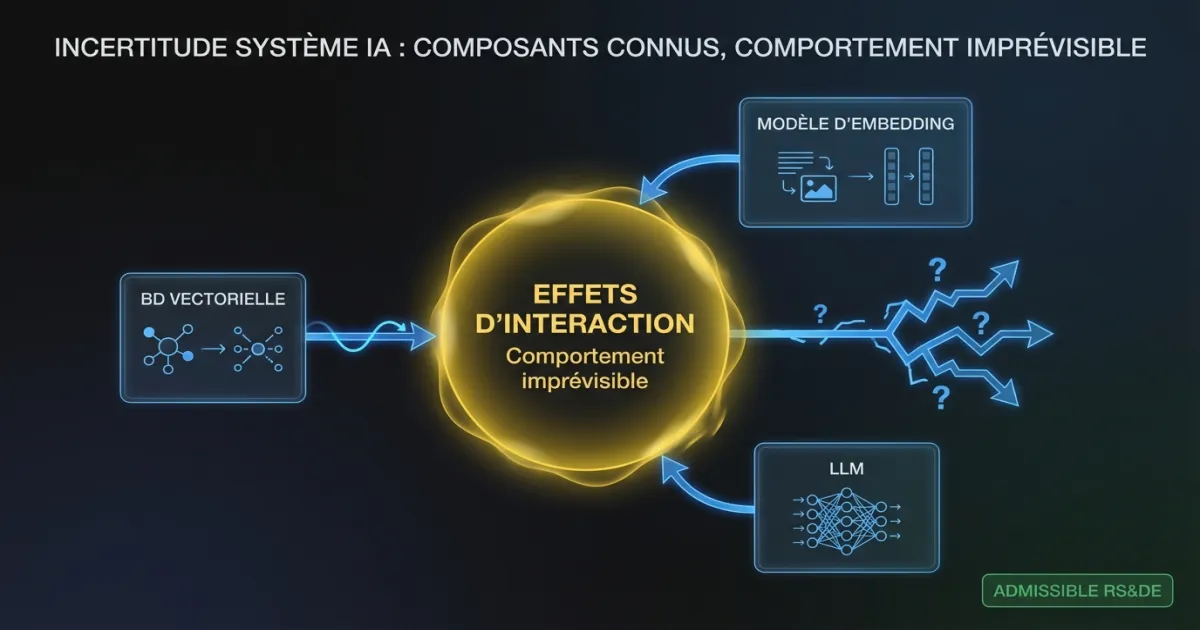
Comment l’incertitude au niveau système renforce-t-elle les réclamations IA/ML?
Un domaine où l’orientation 2026 de l’ARC aide les réclamants : l’incertitude au niveau système. C’est particulièrement pertinent pour les entreprises d’IA/ML.
Une décision de la Cour de l’impôt de 2024 a confirmé que combiner des composants connus peut créer une véritable incertitude technologique lorsque leurs interactions produisent un comportement imprévisible. L’orientation interne mise à jour de l’ARC étend ce principe aux systèmes d’IA/ML explicitement.
Si votre équipe a combiné un système de récupération connu avec un LLM connu et un modèle de re-classement connu, et que l’interaction entre ces composants a produit des modes de défaillance qu’aucune documentation individuelle ne prédisait, l’investigation sur ces effets d’interaction peut se qualifier.
Exemple concret : Votre équipe a construit un système RAG utilisant une base de données vectorielle établie, un modèle d’embedding standard et un LLM commercial. Chaque composant performait selon sa documentation individuellement. Combiné, le système présentait des patrons d’hallucination qui ne survenaient pas avec le LLM seul. Votre équipe a découvert que le composant de récupération faisait remonter des passages sémantiquement similaires mais factuellement contradictoires. Le comportement du LLM face à un contexte contradictoire n’était décrit dans aucune recherche publiée. L’investigation systématique sur cette interaction, et la résolution novatrice développée par votre équipe, se qualifie comme RS&DE.
L’incertitude au niveau système est l’un des angles de réclamation les plus solides pour les entreprises d’IA/ML. Les applications d’IA modernes sont presque toujours des systèmes de composants en interaction. Documentez les interactions, pas seulement les pièces individuelles.
Est-ce que le travail MLOps est admissible à la RS&DE?
L’ARC traite le MLOps de la même manière que le DevOps et le travail d’infrastructure : l’ops en soi ne se qualifie pas, mais résoudre des problèmes techniques novateurs à l’intérieur peut se qualifier.
Ce qui ne se qualifie pas
- Construire des pipelines CI/CD pour le déploiement de modèles
- Implémenter la surveillance standard de modèles (détection de dérive, tableaux de bord de performance)
- Mettre en place une infrastructure de tests A/B pour les variantes de modèles
- Orchestration de conteneurs pour le service de modèles
- Magasins de features standards et pipelines d’ingénierie de features
Ce qui peut se qualifier
- Investiguer une approche novatrice de ré-entraînement en temps réel parce que les méthodes d’apprentissage incrémental existantes ne pouvaient pas gérer la distribution non stationnaire de vos données sans oubli catastrophique
- Développer une nouvelle méthode de détection de dérive conceptuelle dans des modèles multimodaux où les tests statistiques standards produisaient des taux de faux positifs inacceptables
- Rechercher des techniques pour maintenir la cohérence des modèles dans une architecture de service distribuée où les partitions réseau causaient des états de modèles divergents que les protocoles de consensus existants ne pouvaient résoudre
Le patron se maintient : les techniques connues appliquées à de nouvelles situations, c’est de l’ingénierie. Les techniques connues qui échouent dans de nouvelles situations, suivies d’une investigation systématique d’alternatives, c’est là que la RS&DE commence.
Quelle documentation survit à l’examen de l’ARC?
Les réclamations IA/ML nécessitent une documentation au-delà de ce que la plupart des équipes produisent naturellement. Les évaluateurs de l’ARC qui examinent des projets ML cherchent des preuves spécifiques. Pour un guide détaillé des narratifs techniques RS&DE et ce que l’ARC attend dans chaque section du T661, consultez notre guide dédié.
Ce que les évaluateurs veulent voir
Mesures de référence. Avant de prétendre que les méthodes standards ont échoué, montrez que vous les avez essayées et enregistré les résultats. « Nous savions que LoRA ne fonctionnerait pas » n’est pas une incertitude technologique. « Nous avons appliqué LoRA avec les hyperparamètres recommandés et atteint 72 % de précision contre une exigence de 95 % » l’est.
Journaux d’expériences avec métriques spécifiques. Chaque approche testée devrait avoir des entrées, configurations, sorties et résultats quantitatifs documentés. Les commits Git avec horodatage aident. Les outils de suivi d’expériences (Weights & Biases, MLflow, Neptune) produisent exactement les registres que l’ARC valorise.
Articulation claire de ce qui était inconnu. Le narratif T661 doit expliquer ce que votre équipe ne savait pas et pourquoi cette lacune ne pouvait pas être comblée par les connaissances existantes. Pour le travail en IA/ML, cela signifie souvent citer des articles ou techniques spécifiques que vous avez évalués et expliquer pourquoi ils étaient insuffisants.
Preuves de revue de littérature. Les évaluateurs de l’ARC s’attendent de plus en plus à ce que les réclamants IA/ML démontrent qu’ils ont cherché dans la recherche existante avant de conclure qu’une incertitude technologique existait. Si une solution a été publiée dans un article arXiv de 2024 que votre équipe n’a pas trouvé, cela affaiblit la réclamation. Conservez les registres des recherches documentaires effectuées par votre équipe.
Séparation du travail admissible et non admissible. Dans un projet IA/ML, certains travaux se qualifient et d’autres non. La construction de votre pipeline de données ne se qualifie probablement pas. Votre investigation sur pourquoi les architectures standards ont échoué sur vos données se qualifie probablement. L’ARC s’attend à une séparation claire avec allocation de temps pour chacun. Consultez notre guide des activités admissibles RS&DE pour voir où ces lignes tombent typiquement.
Comment structurer le travail IA/ML pour des réclamations défendables?
Si votre entreprise fait de la recherche IA/ML véritable dans le cadre du développement de produits, la façon dont vous structurez et documentez ce travail détermine si votre réclamation survit à l’examen.
Séparez les sprints de recherche de l’ingénierie de production. Quand votre équipe rencontre un problème où les approches connues échouent, créez un flux de travail distinct pour l’investigation. Cela facilite l’identification des heures et activités admissibles. Mélanger recherche et développement routinier dans les mêmes tickets complique le travail de l’ARC. Ils tendent à résoudre l’ambiguïté en défaveur du réclamant.
Documentez l’échec des méthodes connues en premier. Avant d’investiguer des alternatives, enregistrez que vous avez essayé l’approche standard et qu’elle n’a pas fonctionné. Incluez les métriques spécifiques. C’est le fondement de votre réclamation d’incertitude technologique.
Gardez des registres d’expériences granulaires. Chaque approche testée devrait avoir sa propre documentation : l’hypothèse, la méthode, la configuration, le résultat et la conclusion. Les plateformes de suivi d’expériences génèrent cela automatiquement. Si votre équipe n’en utilise pas, commencez.
Rédigez les narratifs techniques au fil du temps. Attendre la période de réclamation pour reconstituer le raisonnement derrière six mois d’expériences ML, c’est comme ça que les réclamations deviennent faibles. Les ingénieurs oublient pourquoi ils ont abandonné l’approche B. Ils ne se souviennent pas des métriques spécifiques de la troisième expérience. Des brouillons narratifs mensuels ou trimestriels, même sommaires, préservent le détail qui rend les réclamations défendables.
Connaissez la frontière avant de commencer. Chaque problème ML difficile n’est pas un problème RS&DE. Avant d’allouer un effort significatif à un défi technique, demandez : est-ce qu’un praticien qualifié pourrait résoudre cela en appliquant des techniques connues? Si oui, c’est de l’ingénierie. Si non, et que vous pouvez articuler pourquoi, vous avez peut-être un projet admissible. Faire cette évaluation tôt, et la documenter, renforce la réclamation.
Pour des exemples RS&DE concrets à travers différents types de R&D logicielle, incluant des projets IA/ML, consultez notre bibliothèque d’exemples. Si vous êtes préoccupé par un potentiel audit RS&DE, comprendre le processus d’examen de l’ARC avant de déposer est toujours mieux que de l’apprendre après.
FAQ
Est-ce que tout le travail en IA/ML est admissible aux crédits d’impôt RS&DE?
Non. La plupart du travail en IA/ML dans les entreprises logicielles est de l’application de technologie existante, pas de l’avancement. Utiliser des modèles établis, ajuster avec des méthodes documentées et déployer avec des pipelines standards ne se qualifie pas. Le travail se qualifie seulement quand les techniques connues échouent, que vous investiguez des alternatives systématiquement et que vous produisez de nouvelles connaissances techniques.
Pourquoi l’ARC rejette-t-elle autant de réclamations de prompt engineering?
Le prompt engineering est de l’optimisation utilisant un outil connu. Rédiger, tester et itérer sur des prompts est un processus d’ingénierie, pas une activité de recherche. L’ARC le traite de la même façon que l’ajustement de paramètres de configuration. Il peut soutenir un projet admissible plus large, mais il ne crée pas d’admissibilité RS&DE en soi.
Quel est l’angle de réclamation RS&DE le plus solide pour les entreprises d’IA/ML?
L’incertitude au niveau système. L’orientation 2026 de l’ARC et une décision de la Cour de l’impôt de 2024 reconnaissent toutes deux que combiner des composants connus peut créer une véritable incertitude technologique lorsque leurs interactions produisent un comportement imprévisible. La plupart des applications d’IA modernes sont des systèmes de composants en interaction, faisant de cela un angle de réclamation naturel et défendable.
Vous ne savez pas où votre travail en IA/ML se situe sur la ligne d’admissibilité? Parlez à notre équipe RS&DE. Nous aidons les entreprises logicielles à identifier le R&D admissible, structurer la documentation qui survit à l’examen de l’ARC et maximiser les réclamations sans dépasser les limites.