Point clé
Les workflows IA en production exigent cinq patterns : modèle d'exécution adapté, gestion d'état en niveaux, chemins de récupération explicites, points de contrôle humains pour les actions critiques, et observabilité structurée dès le départ.
La plupart des équipes d’ingénierie qui commencent à construire des workflows IA agentiques vivent la même expérience : la première version fonctionne. La démo tourne bien. Les appels LLM s’exécutent, les outils répondent, le résultat semble correct. Puis on le met devant de vrais utilisateurs avec de vraies données, et tout commence à se dérégler.
L’agent s’emmêle en plein workflow. L’état d’une exécution contamine la suivante. Un outil renvoie un format de réponse inattendu et toute la chaîne échoue silencieusement. Impossible de comprendre à partir des logs pourquoi il a pris cette décision.
Les appels LLM ne sont pas là où les vrais problèmes résident. Ceux-là sont en grande partie résolus : choisir un modèle capable, écrire un bon prompt système, définir ses outils. La difficulté, c’est tout ce qui entoure les appels LLM. La gestion d’état. La récupération après erreur. L’observabilité. La logique d’orchestration. C’est là que s’ouvre l’écart entre une démo et un système en production.
Cet article couvre cinq patterns d’architecture qui comblent cet écart. Ils sont indépendants du framework. Que vous construisiez sur LangGraph, AutoGen, une couche d’orchestration personnalisée, ou des appels API directs, ces patterns s’appliquent.
Pourquoi l’architecture des workflows agentiques est-elle plus complexe qu’il n’y paraît ?
Un appel LLM unique est simple à raisonner. Une entrée rentre, une sortie sort. Si la sortie est mauvaise, on ajuste le prompt.
Un workflow d’agent multi-étapes n’est pas simple à raisonner. La sortie de chaque étape devient l’entrée de la suivante. Les erreurs s’accumulent. Une extraction incorrecte à l’étape 2 influence chaque décision que l’agent prend aux étapes 3 à 8. Quand vous voyez un mauvais résultat à la fin, la chaîne causale remonte plusieurs étapes en arrière et peut impliquer un comportement non déterministe du modèle qui ne se reproduit pas de façon cohérente.
Il y a ici un problème mathématique de composition. Un agent qui exécute un workflow de 10 étapes à 95 % de précision par étape produit le résultat final correct environ 60 % du temps. À 20 étapes, cela tombe à 36 %. Cela implique que les exigences de fiabilité par étape dans les workflows agentiques sont bien plus strictes qu’elles n’en ont l’air. Viser “à peu près juste” à chaque étape ne suffit pas.
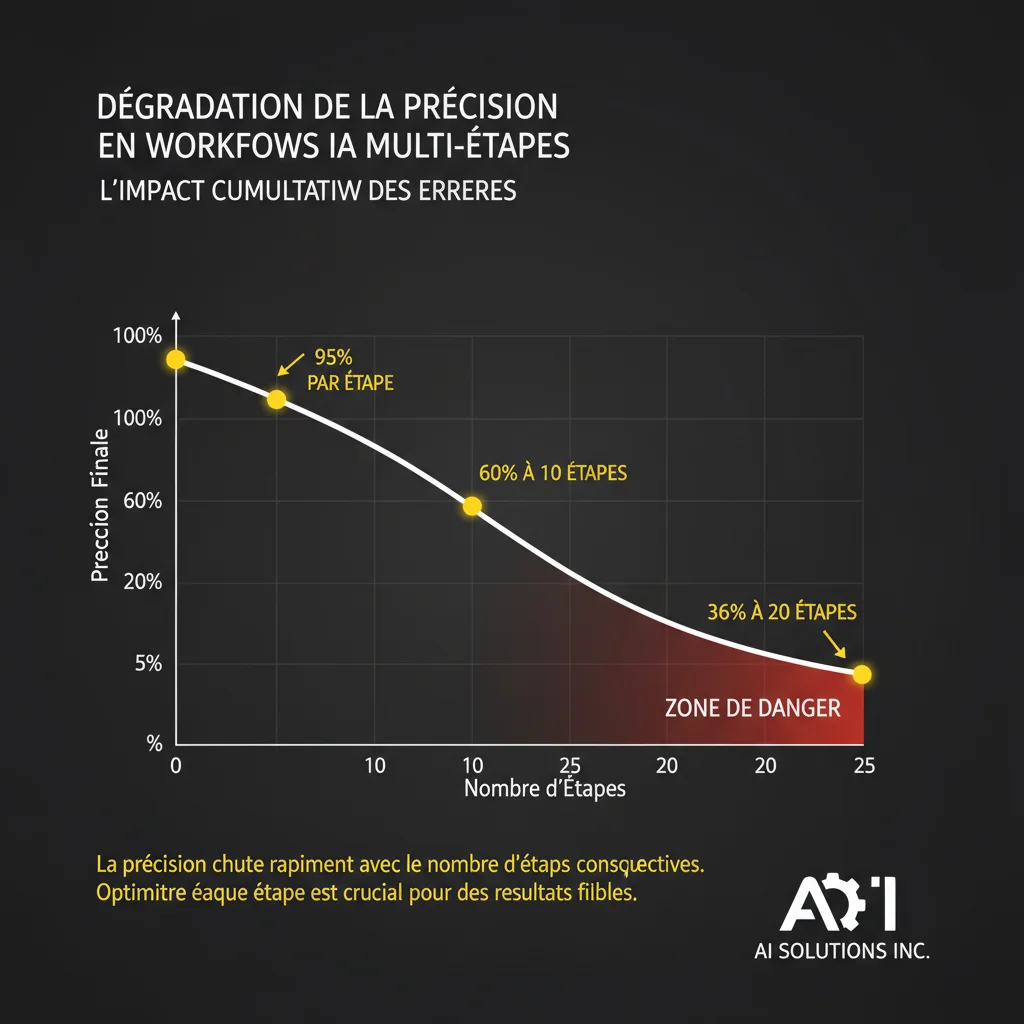
Les erreurs composées ne sont pas le seul problème. Les workflows agentiques en production doivent aussi gérer :
La continuité d’état entre opérations asynchrones. Si votre agent distribue le traitement de 50 documents en parallèle et que trois échouent à mi-chemin, où reprend le workflow ? Qu’advient-il du travail qui s’est terminé avec succès ?
Les actions irréversibles. Les agents qui écrivent dans des bases de données, envoient des e-mails ou appellent des API externes prennent des actions aux conséquences réelles. Le processus de raisonnement de l’agent est non déterministe, mais les actions qu’il déclenche ne sont pas réversibles.
L’évaluation sans sorties déterministes. Les tests logiciels traditionnels vérifient des sorties exactes. Les workflows agentiques sont non déterministes. La même entrée peut produire des sorties différentes d’une exécution à l’autre. Votre suite de tests doit vérifier des comportements, pas des chaînes de caractères.
Les lacunes d’observabilité. Quand un agent prend une mauvaise décision, vous devez comprendre pourquoi. Les logs d’application standard ne capturent pas la chaîne de raisonnement de l’agent, les appels d’outils qu’il a faits, les données qu’il a transmises, ni la logique qui l’a conduit à l’action prise.
Ce sont ces problèmes que les patterns suivants sont conçus à résoudre.
Pattern 1 : Exécution séquentielle vs. parallèle
La première décision d’architecture dans tout workflow agentique est de savoir si les étapes s’exécutent séquentiellement ou en parallèle. La plupart des équipes choisissent le séquentiel par défaut parce que c’est plus simple à raisonner. Ce réflexe est souvent erroné.
L’exécution séquentielle est correcte quand chaque étape dépend de la sortie de l’étape précédente. Un workflow de support client qui classe un ticket, puis recherche le contexte du compte en fonction de cette classification, puis rédige une réponse en fonction du contexte du compte s’exécute séquentiellement parce que l’ordre est une dépendance. On ne peut pas rédiger la réponse avant de connaître le contexte du compte.
L’exécution parallèle est correcte quand les étapes sont indépendantes. Un agent qui traite 50 documents financiers pour produire un rapport de synthèse n’a pas besoin d’attendre que le document 1 soit terminé avant de commencer le document 2. Distribuez, traitez les 50 simultanément, puis agrégez. La différence de latence est significative : à 3 secondes par document, le traitement séquentiel prend 150 secondes. Le traitement parallèle prend 3 secondes plus le temps d’agrégation.
L’implémentation pratique requiert quelques éléments que les workflows séquentiels n’ont pas :
Un coordinateur scatter-gather qui lance les workers parallèles, suit leur état de complétion, et attend que tous aient terminé (ou gère gracieusement la complétion partielle) avant de continuer. C’est distinct d’un orchestrateur LLM — c’est généralement une logique de planification déterministe autour des appels LLM.
L’isolation des workers. Les workers parallèles ont besoin de leur propre contexte. Si vous utilisez une fenêtre de contexte partagée, les workers contamineront mutuellement leur raisonnement. Chaque branche parallèle doit recevoir exactement le contexte dont elle a besoin pour sa tâche spécifique, rien de plus.
La logique d’agrégation. Après la distribution, il faut fusionner les résultats. Pour les tâches d’extraction, c’est souvent simple — combiner les champs extraits de 50 documents en un seul schéma. Pour les tâches analytiques, l’étape d’agrégation peut elle-même nécessiter un appel LLM pour synthétiser les résultats parallèles en un tout cohérent.
L’erreur classique : traiter un workflow parallélisable comme séquentiel parce que c’est plus facile à construire. Si votre workflow traite un lot d’entrées indépendantes, distribuez. Le gain en latence et en coût est souvent d’un ordre de grandeur.
Pattern 2 : Gestion d’état sans saturer la fenêtre de contexte
La gestion d’état est là où la plupart des workflows agentiques tombent en premier.
L’approche naïve : tout mettre dans la fenêtre de contexte. Chaque résultat d’appel d’outil, chaque sortie intermédiaire, chaque décision que l’agent a prise jusqu’ici. Ça fonctionne pour les workflows courts. Ça échoue pour les longs. Les fenêtres de contexte sont larges — 128K tokens pour GPT-4 Turbo et 200K pour Claude paraissent généreux — mais elles se remplissent plus vite que prévu quand on accumule des sorties d’outils, l’historique de conversation et des résultats intermédiaires sur une douzaine d’étapes.
Plus important encore, un contexte saturé dégrade les performances. Les LLM attentifs sur un long contexte ne pondèrent pas l’information uniformément. Le contenu plus ancien reçoit moins d’attention. L’agent oublie effectivement des choses qui sont techniquement encore dans le contexte. Les développeurs décrivent cela comme une “dérive de contexte” — l’agent cesse de référencer des informations auxquelles il a clairement accès.
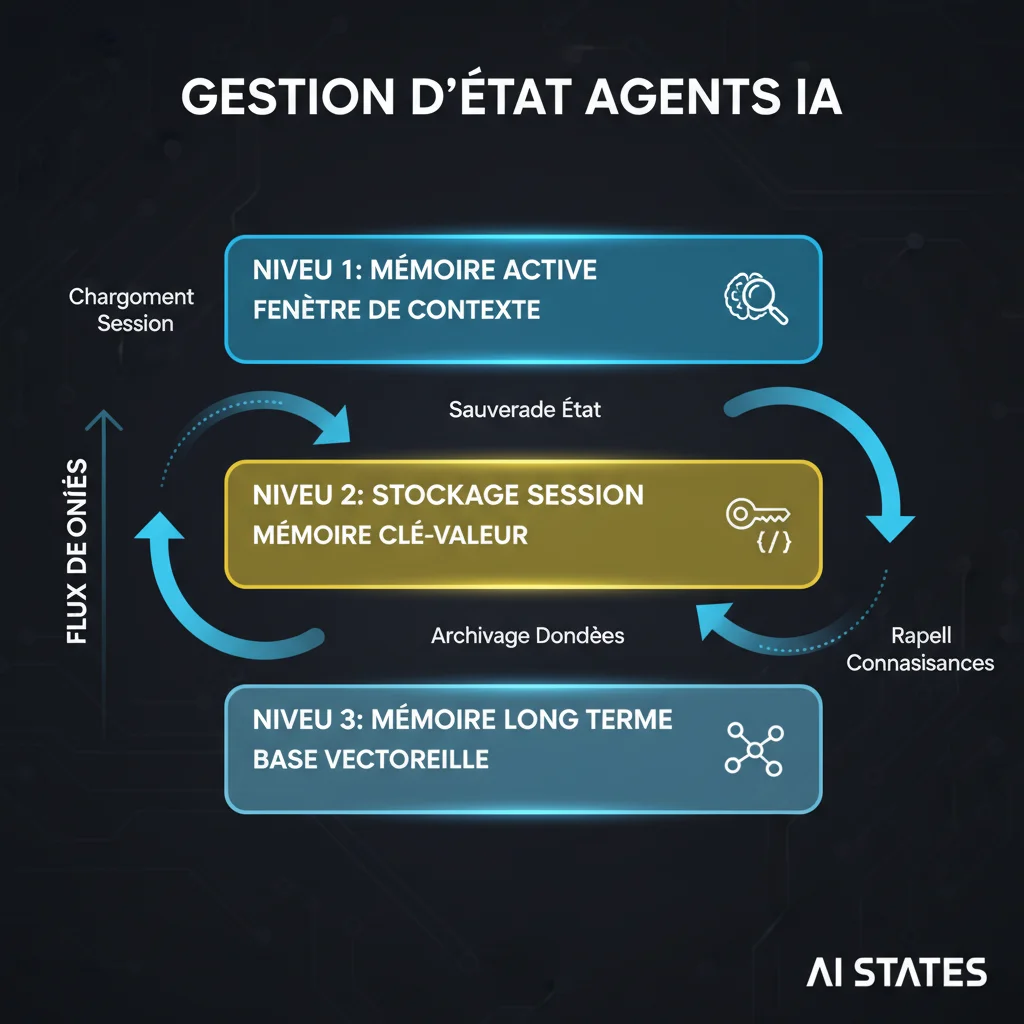
La gestion d’état en production utilise un modèle en niveaux :
La mémoire active vit dans la fenêtre de contexte. C’est l’information dont l’agent a besoin maintenant : la tâche courante, la sortie de l’étape immédiatement précédente, et le schéma structuré qu’il remplit. Gardez ça serré. Quand un outil renvoie un résultat de 10 000 tokens et que l’agent n’a besoin que de trois champs, extrayez ces champs et jetez le reste avant de passer à l’étape suivante.
Le stockage de session à court terme vit hors de la fenêtre de contexte, dans un store clé-valeur ou une base de données structurée. C’est l’état accumulé pour l’exécution du workflow en cours : quelles étapes ont été complétées, quelles données ont été extraites, quelles décisions ont été prises. L’agent récupère des champs spécifiques du stockage de session au besoin plutôt que de tout charger dans le contexte.
La mémoire long terme vit dans un vector store ou une base de connaissances structurée. C’est le contexte inter-sessions : préférences utilisateur, patterns historiques, connaissances métier acquises. Récupéré au moment de l’inférence via recherche sémantique, avec filtrage de pertinence pour garder le contexte récupéré gérable.
L’architecture pour injecter l’état dans le contexte a son importance. Plutôt que de charger tout l’état stocké, concevez des étapes explicites d‘“assemblage de contexte” qui récupèrent exactement ce dont l’étape suivante a besoin. Avant une étape de rédaction, récupérez uniquement les champs extraits pertinents. Avant une étape de décision, récupérez les contraintes accumulées plus la tâche courante. Traitez l’assemblage de contexte comme une opération de première classe dans votre conception de workflow.
Un pattern qui fonctionne bien : des objets d’état structurés avec des champs explicites plutôt qu’une accumulation libre dans le contexte. Au lieu d’ajouter les sorties d’outils à un historique de conversation, écrivez les résultats dans des champs typés d’un objet d’état. L’agent lit et écrit dans cet objet à chaque étape. L’objet d’état devient la source de vérité pour le workflow. Ce qui est dans le contexte à un moment donné est le sous-ensemble de l’état pertinent pour la tâche de cette étape.
Pattern 3 : Modes de défaillance et récupération
Les workflows agentiques échouent de plus de façons que les logiciels conventionnels. La taxonomie des défaillances vaut la peine d’être comprise avant de concevoir la logique de récupération.
Les défaillances déterministes sont des erreurs logicielles standard : un outil renvoie un 500, une connexion base de données expire, une limite de taux API se déclenche. Elles sont récupérables avec une logique de retry standard. Utilisez un backoff exponentiel avec jitter. Définissez des compteurs de retry maximum. Faites échouer l’étape proprement si les retries sont épuisés pour que l’orchestrateur puisse gérer plutôt que l’agent tourne en boucle.
Les défaillances sémantiques sont spécifiques aux systèmes agentiques : le LLM produit un appel d’outil avec des paramètres invalides, extrait les mauvais champs d’un document, ou fait une erreur logique dans son raisonnement qui produit un mauvais résultat intermédiaire. Celles-ci ne lèvent pas d’exception. Elles produisent des sorties incorrectes qui ressemblent à des sorties correctes pour la couche d’exécution. C’est le mode de défaillance le plus difficile.
Les défaillances en cascade surviennent quand une défaillance sémantique à une étape se propage dans le workflow. L’agent fait une mauvaise classification à l’étape 2. Chaque étape suivante opère sur cette erreur de classification. La sortie finale est faussement confidente. Le temps que vous le détectiez, plusieurs appels d’outils ont été exécutés sur de mauvaises prémisses.
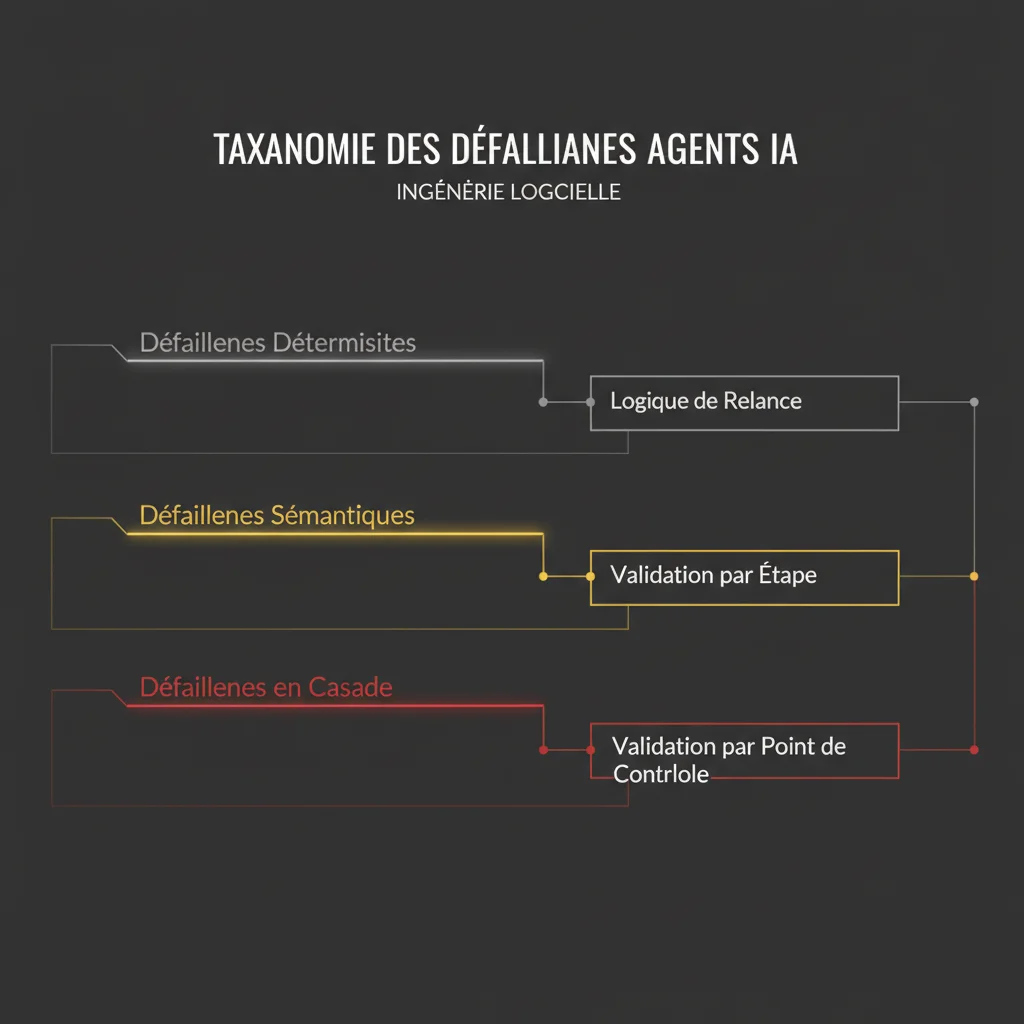
Patterns de récupération pour chacun :
Pour les défaillances déterministes, la récupération est retry-puis-échec. Définissez des budgets de retry par outil. Après épuisement des retries, exécutez le chemin de repli : routez vers une file humaine, substituez une réponse dégradée, ou faites échouer tout le workflow avec une erreur structurée que les systèmes en aval peuvent gérer. L’essentiel est que les replis soient explicites dans la conception du workflow, pas gérés par le jugement de l’agent. Les agents auxquels on demande de “faire de leur mieux” quand un outil échoue hallucinent souvent leur chemin.
Pour les défaillances sémantiques, la défense principale est la validation par étape. Après chaque étape, vérifiez la sortie contre un schéma ou un ensemble de contraintes explicites avant de la transmettre à l’étape suivante. Une étape d’extraction doit produire des champs qui correspondent aux types et plages de valeurs attendus. Une étape de classification doit produire un label de classe qui existe dans votre taxonomie définie. Si la sortie ne passe pas la validation, l’étape échoue et peut être réessayée avec un prompt modifié ou escaladée vers une revue humaine.
Pour les défaillances en cascade, le correctif structurel est la validation par point de contrôle entre les phases majeures du workflow. Ne lancez pas 10 étapes d’affilée en vérifiant la sortie à la fin. Définissez des phases de workflow avec des points de contrôle explicites. À chaque point de contrôle, une étape de validation confirme que l’état accumulé est cohérent avant que la phase suivante commence. Cela limite le rayon d’action d’une défaillance sémantique à une phase plutôt qu’à tout le workflow.
Les chemins d’escalade humaine méritent une attention explicite à la conception. La question n’est pas de savoir s’il faut les inclure — vous devriez toujours les inclure. La question est où ils se déclenchent et quelle information ils font remonter. Un humain qui révise une étape de workflow escaladée a besoin du contexte complet : ce que l’agent essayait de faire, ce qu’il a fait, quelle était la sortie, et pourquoi la validation a échoué. Concevez l’interface d’escalade avant de concevoir l’agent, pas après.
Pattern 4 : Points de contrôle humains dans la boucle
L’autonomie totale est appropriée pour un ensemble de tâches plus étroit que la plupart des équipes ne le supposent initialement. Pour la plupart des workflows en production, les points de contrôle humains dans la boucle (HITL) ne sont pas une concession aux préoccupations de sécurité. C’est une bonne architecture.
Les décisions à prendre en amont : quelles actions nécessitent une approbation humaine, dans quelles conditions, et à quoi ressemble l’interface d’approbation.
Où les points de contrôle HITL ont leur place :
Les actions irréversibles ou à fort enjeu. Envoyer des communications externes, modifier la facturation, supprimer des enregistrements, publier du contenu publiquement. Jusqu’à ce que le taux d’erreur de votre agent pour ces types d’actions ait été mesuré et validé par rapport à votre seuil de tolérance, exigez une approbation.
Les décisions qui franchissent un seuil de confiance. Si votre agent produit une classification ou une extraction avec un score de confiance en dessous d’un niveau défini, routez vers une revue humaine plutôt que de continuer. La plupart des APIs de modèles renvoient des logprobs ou des signaux de confiance utilisables à cette fin. Intégrez le routage basé sur la confiance dans votre workflow dès le départ.
Les entrées nouvelles. Si une requête entrante ne correspond pas à la distribution pour laquelle votre agent a été conçu, un routeur qui détecte les entrées hors distribution et les escalade empêche l’agent de produire des réponses faussement confiantes sur des entrées pour lesquelles il n’a pas été conçu.
La revue planifiée pour les décisions à fort volume. Même les actions que l’agent gère de façon autonome devraient passer par une revue humaine périodique. Un agent de triage de support traitant 1 000 tickets par jour pourrait fonctionner de façon entièrement autonome sur les tickets individuels mais remonter un lot quotidien de 20 décisions échantillonnées aléatoirement pour une revue qualité. C’est ainsi qu’on détecte la dérive comportementale avant qu’elle ne s’accumule en un problème plus large.
Concevoir l’interface d’approbation :
L’interface n’est pas une réflexion après coup. Un point de contrôle HITL qui affiche un mur de texte sans structure sera approuvé de façon réflexive plutôt qu’examiné attentivement. Concevez l’interface d’approbation pour montrer au réviseur exactement ce dont il a besoin pour prendre une bonne décision : la requête entrante, l’action proposée par l’agent, le contexte pertinent, et un contrôle approuver/rejeter clair avec l’option de modifier l’action proposée avant d’approuver.
Les flux d’approbation asynchrones qui ne bloquent pas le workflow valent l’investissement en ingénierie. Un workflow qui se met en pause indéfiniment en attendant une entrée humaine est fragile en production. Construisez des files d’approbation que le workflow interroge, avec une gestion des timeouts qui escalade ou échoue gracieusement si l’approbation n’arrive pas dans une fenêtre définie.
Pattern 5 : Observabilité pour les workflows agentiques
Les workflows agentiques ont un problème d’observabilité que la surveillance d’application conventionnelle ne résout pas.
La journalisation standard capture des événements : requête reçue, fonction appelée, réponse renvoyée. Pour un service déterministe, c’est suffisant. Pour un workflow agentique, vous avez besoin de plus. Vous avez besoin de la chaîne de raisonnement de l’agent : ce qu’il a observé, ce qu’il a décidé de faire, pourquoi il a pris cette décision, quels outils il a appelés, ce que ces outils ont renvoyé, et comment il a incorporé ces résultats dans sa décision suivante.
Sans cette trace, déboguer les défaillances d’un agent revient à deviner ce qui s’est passé à l’intérieur d’un système non déterministe.
Traces structurées pour les décisions d’agent :
Chaque décision d’agent doit produire un événement de trace structuré, pas juste une ligne de log. L’événement de trace capture : le nom de l’étape, l’état d’entrée, l’appel modèle (prompt, paramètres, version du modèle), la réponse (texte de sortie, appels d’outils), les résultats des appels d’outils le cas échéant, le résultat de validation pour la sortie de cette étape, et l’étape suivante vers laquelle le workflow a transitionné. C’est plus de données que la journalisation conventionnelle, mais c’est le minimum requis pour déboguer une défaillance d’agent non triviale.
Les spans OpenTelemetry correspondent bien aux étapes d’agent. Chaque étape devient un span avec les champs ci-dessus comme attributs. La racine de la trace est l’invocation du workflow. Les spans enfants sont les étapes individuelles. Les appels d’outils sont des spans enfants de l’étape qui les a déclenchés. Cela vous donne la latence de bout en bout, le timing par étape, et une vue hiérarchique de ce que l’agent a fait pendant une exécution de workflow donnée.
Plusieurs plateformes d’observabilité ont développé un support natif pour le tracing LLM (LangSmith, Braintrust, Helicone, Langfuse en sont des exemples). L’outillage spécifique importe moins que l’engagement à capturer des traces structurées dès le départ. Ajouter l’observabilité a posteriori dans un agent de production est douloureux. Intégrez-la dès le premier jour.
Boucles d’évaluation :
Le tracing vous dit ce qui s’est passé. L’évaluation vous dit si c’était correct.
Construire une boucle d’éval nécessite trois choses : un jeu de données d’entrées représentatives avec les comportements attendus, une fonction d’évaluation qui score les sorties par rapport à ces attentes, et un pipeline qui exécute les evals à chaque déploiement et remonte les régressions.
La fonction d’évaluation n’a pas besoin de comparer des chaînes exactes. Pour la plupart des tâches d’agent, vous évaluez des catégories de correction : l’agent a-t-il appelé les bons outils ? A-t-il extrait les champs correctement ? A-t-il routé vers le bon chemin ? La sortie finale répond-elle aux exigences pour ce type de tâche ? Les juges d’évaluation basés sur LLM fonctionnent bien ici — un modèle de notation qui évalue la sortie de l’agent par rapport à une grille d’évaluation passe mieux à l’échelle que la logique d’évaluation codée à la main.
En production, surveillez les métriques qui signalent la dérive comportementale. Pour un agent de classification : la distribution des classes dans le temps (des changements soudains indiquent que le comportement de classification de l’agent a changé). Pour un agent d’extraction : les scores de confiance par champ (une confiance déclinante sur des champs spécifiques indique un changement de format dans les documents entrants). Pour un agent de rédaction de réponse : les taux d’approbation humaine (des taux d’approbation déclinants indiquent que la qualité de sortie de l’agent s’est dégradée).
Questions fréquentes
Pourquoi les workflows agentiques échouent-ils en production alors qu’ils fonctionnaient en démo ?
Les environnements de démo utilisent des entrées propres et prévisibles. La production expose les vrais modes de défaillance : contamination d’état entre exécutions, erreurs d’outils qui ne lèvent pas d’exception, défaillances sémantiques où le LLM extrait silencieusement les mauvaises données, et dérive de contexte quand la fenêtre de contexte se remplit. Les patterns qui préviennent ces défaillances ne sont pas visibles avant d’être en production.
Quelle est la pièce d’infrastructure la plus importante pour les agents en production ?
L’observabilité structurée. Sans traces qui capturent la chaîne de raisonnement de l’agent — ce qu’il a observé, décidé et fait à chaque étape — déboguer des défaillances revient à deviner à l’intérieur d’un système non déterministe. Construisez le tracing avant de construire l’agent, pas après.
Comment gérer le problème de précision composée dans les workflows multi-étapes ?
De deux façons : réduire les étapes quand c’est possible (moins d’étapes signifie moins de composition), et ajouter une validation par étape qui attrape les défaillances sémantiques avant qu’elles ne se propagent. Un agent à 95 % de précision par étape n’atteint que 60 % de précision finale sur 10 étapes. La validation par point de contrôle limite le rayon d’action de la défaillance de n’importe quelle étape.
L’infrastructure dont vous avez besoin avant d’écrire le premier appel agent
Les patterns ci-dessus ne valent que ce que vaut l’infrastructure sur laquelle ils s’appuient. Avant d’écrire le premier appel LLM dans un système de production, vous avez besoin de :
Un store d’état. Un endroit pour persister l’état du workflow entre les étapes. Redis fonctionne pour l’état de session éphémère. Une base de données relationnelle ou un store de documents fonctionne pour l’état de workflow durable. Le choix dépend de vos exigences de durabilité, mais quelque chose d’autre que la fenêtre de contexte est nécessaire.
Une file de tâches. Pour les workflows asynchrones et de longue durée, une file de tâches (Celery, BullMQ, Temporal, SQS) gère l’exécution des étapes, la logique de retry et la concurrence. Temporal ou des outils d’orchestration de workflow similaires sont particulièrement bien adaptés aux workflows agentiques parce qu’ils gèrent nativement l’état distribué, les retries et les timeouts.
Un pipeline de tracing. L’instrumentation OpenTelemetry dès le départ. Que vous envoyiez les traces à Datadog, Honeycomb, Grafana ou une plateforme spécifique aux LLM est secondaire. Ce qui compte, c’est que vous capturiez des traces structurées avant d’avoir des utilisateurs.
Un harnais d’évaluation. Un exécuteur de tests qui exécute un jeu de données représentatif contre l’agent et score les sorties. Une étape CI qui exécute les evals sur chaque pull request vers le code ou les prompts de l’agent.
Une passerelle LLM. Une couche devant vos appels API de modèle qui gère la limitation de taux, le suivi des coûts, le routage de modèle et la mise en cache. Sans elle, vous découvrirez votre structure de coûts en production sous charge plutôt qu’en conception. LiteLLM et des couches de routage similaires fournissent cela comme infrastructure plutôt que comme code personnalisé.
Des chemins de repli pour chaque outil. Avant d’écrire la logique agent, définissez ce qui se passe quand chaque outil dont l’agent dépend est indisponible. Certains replis sont une dégradation gracieuse (continuer sans les données, les signaler comme manquantes). Certains sont des arrêts complets (si l’API de paiement est en panne, ne tentez pas de traiter des paiements). Définissez ceux-ci avant que l’agent passe en production.
Cette liste d’infrastructure n’est pas exotique. La plupart de ces composants existent dans une organisation d’ingénierie de production mature. Ce qui est différent pour les systèmes agentiques, c’est qu’ils sont porteurs de charge dès le premier jour, pas des ajouts optionnels. Un workflow agentique sans store d’état est fragile. Un agent sans tracing structuré est impossible à déboguer. Un agent sans evals livre des régressions comportementales invisiblement.
Les patterns décrits ici s’appliquent quel que soit le framework que vous utilisez. Le modèle d’exécution en graphe de LangGraph, la coordination multi-agents d’AutoGen, les primitives de workflow durables de Temporal — chacun exprime ces mêmes patterns dans son propre idiome. Le framework s’occupe de la plomberie. Les décisions d’architecture sont les vôtres.
Si votre équipe travaille sur la construction de l’infrastructure pour un système d’agents en production et souhaite un soutien en ingénierie de personnes qui ont déployé ces systèmes dans des environnements de production, c’est ce que nous faisons. Contactez-nous pour discuter de votre architecture.