Point clé
L'APM standard affiche un tableau de bord vert pendant que votre agent donne de mauvaises réponses. La surveillance des agents en production exige le suivi de la dérive d'hallucination, des boucles d'appels d'outils, de l'épuisement du contexte et du taux de consommation des coûts avec des outils d'observabilité dédiés comme Langfuse ou LangSmith.
Votre agent est en production. Il a passé les évaluations. Il a survécu à la démo sans gêner personne. L’équipe produit est contente. L’équipe technique est prudemment optimiste.
Six semaines plus tard, un client signale que l’agent a recommandé de supprimer un index de base de données de production. Les logs montrent une réponse 200 propre avec 340ms de latence. Selon tous les indicateurs traditionnels, rien n’a mal tourné. Mais quelque chose a clairement dérapé.
Surveiller des agents IA en production exige un modèle mental différent de celui du logiciel traditionnel. Les modes de défaillance sont différents. Les signaux sont différents. Les outils que vous avez déjà couvrent environ 30 % de ce dont vous avez besoin.
Pourquoi l’APM traditionnel est-il insuffisant pour les agents IA?
Datadog, New Relic et les plateformes similaires reposent sur un modèle bien compris : les requêtes arrivent, le traitement se fait, les réponses sortent. On suit les percentiles de latence, les taux d’erreur, le débit et l’utilisation des ressources. Quand quelque chose casse, ça se voit dans un taux d’erreur élevé ou un pic de latence.
Les agents IA cassent ce modèle d’une façon précise. Un agent peut retourner une réponse HTTP réussie, dans les limites normales de latence, avec un payload JSON bien formé, et le contenu de ce payload peut être complètement faux. L’agent a halluciné un paramètre d’outil. Il a pris une décision basée sur un contexte de trois tours plus tôt qui n’était plus pertinent. Il a appelé la même API quatre fois parce qu’il ne pouvait pas analyser correctement la réponse.
Rien de tout ça n’apparaît dans votre tableau de bord APM. La requête a réussi. La latence était correcte. Le taux d’erreur n’a pas bougé. Votre stack de monitoring traditionnel vous affiche un tableau de bord vert pendant que votre agent donne de mauvais conseils à un client.
Ça ne veut pas dire qu’on jette l’APM. Vous en avez encore besoin pour la santé de l’infrastructure, la disponibilité des API et le suivi de performance de base. Mais ça devient le plancher, pas le plafond.
Quels sont les cinq modes de défaillance à surveiller?
Après avoir exploité des systèmes d’agents dans plusieurs déploiements en production, voici les schémas de défaillance qui causent de vrais dommages. Ils ont un trait commun : ils sont invisibles au monitoring standard.
Dérive d’hallucination
Les hallucinations ne sont pas binaires. Un agent ne se met pas subitement à inventer des choses. Il dérive. La qualité des sorties se dégrade graduellement à mesure que le contexte s’accumule dans les longues conversations, que les fournisseurs de modèles poussent des mises à jour silencieuses, ou que la distribution des entrées en production s’éloigne de ce que votre suite d’évaluation couvre.
Semaine un, l’agent produit 94 % de réponses factuellement correctes. Semaine six, on est à 87 %. Personne ne remarque parce qu’aucun indicateur ne le suit. La dégradation ne fait surface que quand un client escalade ou quand quelqu’un vérifie manuellement les sorties.
Surveiller ça exige une évaluation continue contre le trafic de production. Échantillonnez 5 à 10 % des réponses, passez-les dans un pipeline de notation, et suivez la tendance. Une baisse de 3 points en deux semaines mérite investigation, même si aucune réponse individuelle n’a déclenché d’alerte.
Boucles d’appels d’outils
Un agent qui peut appeler des outils externes va parfois se bloquer. Il appelle l’API de recherche, obtient des résultats qu’il ne peut pas analyser, reformule la requête, obtient des résultats similaires, reformule encore, et répète. Chaque appel d’outil individuel réussit. L’agent « fonctionne ». Mais il brûle des jetons et du temps sans progresser.
Dans un système que nous avons observé, un agent faisait en moyenne 3,2 appels d’outils par requête en fonctionnement normal. Pendant un week-end, une API tierce a légèrement changé son format de réponse. Lundi matin, la moyenne était de 11,4 appels d’outils par requête. La latence a triplé. Les coûts ont quadruplé. Le taux d’erreur est resté à zéro.
Suivez les appels d’outils par requête comme une distribution, pas juste une moyenne. Alertez quand le 95e percentile dépasse 2x la ligne de base des 7 derniers jours.
Épuisement de la fenêtre de contexte
Chaque LLM a une fenêtre de contexte finie. Quand le contexte accumulé d’un agent (prompt système, historique de conversation, résultats d’outils, documents récupérés) approche cette limite, le modèle commence à supprimer de l’information. Il ne génère pas d’erreur. Il ne vous avertit pas. Il tronque silencieusement, et l’agent perd l’accès aux instructions ou au contexte dont il a besoin pour prendre de bonnes décisions.
C’est particulièrement dangereux dans les conversations multi-tours et les cas d’utilisation d’IA agentique où l’agent accumule des résultats d’outils sur plusieurs étapes. Un agent augmenté par RAG qui récupère quatre documents par tour peut épuiser une fenêtre de contexte de 128K en moins de 20 tours.
Journalisez l’utilisation des jetons à chaque étape. Suivez le ratio de jetons utilisés par rapport à la limite de contexte du modèle. Alertez quand une requête dépasse 80 % de la fenêtre. Considérez ça comme un problème de conception, pas juste de monitoring. Si vous atteignez régulièrement 80 %, votre stratégie de gestion du contexte a besoin de travail.
Dégradation de la latence par dépendances séquentielles
Un simple appel API prend 200ms. Un agent qui raisonne, appelle un outil, lit le résultat, raisonne encore, appelle un autre outil et synthétise une réponse enchaîne cinq ou six opérations séquentielles. Chacune prend 200 à 2000ms selon le temps d’inférence du modèle, le temps de réponse de l’outil et la vitesse de récupération RAG.
La latence de bout en bout pour une seule requête d’agent peut facilement atteindre 8 à 15 secondes. Et c’est variable. Une file d’attente de modèle froide ajoute 2 secondes. Une requête lente à la base de données vectorielle en ajoute une autre. Ça se compose de façon imprévisible.
Suivez la latence par étape, pas juste de bout en bout. Instrumentez chaque étape de raisonnement, chaque appel d’outil et chaque opération de récupération avec son propre span. C’est là qu’OpenTelemetry prend toute sa valeur : vous pouvez voir exactement quelle étape dans une requête de 12 secondes a pris 6 secondes.
Effondrement de la confiance
Certains agents produisent des scores de confiance ou peuvent être sollicités pour exprimer leur incertitude. Le schéma dangereux, c’est quand l’agent génère des sorties à faible confiance mais agit quand même dessus. Il n’est « pas sûr » si l’utilisateur demande la facturation ou la suppression de compte, mais il procède avec l’interprétation facturation et exécute un remboursement.
Si votre architecture d’agent inclut une forme de notation de confiance, suivez la distribution des scores de confiance dans le temps. Un glissement vers la gauche (plus de réponses à faible confiance) précède souvent un pic de plaintes clients de 1 à 2 semaines. C’est un indicateur avancé que quelque chose dans la distribution des entrées ou le comportement du modèle a changé.

Que faut-il journaliser et tracer dans un système d’agent IA?
L’instinct par défaut est de journaliser les entrées et les sorties. Ça capture peut-être 20 % de ce dont vous avez besoin pour déboguer un problème d’agent en production. La chaîne de raisonnement entre l’entrée et la sortie, c’est là que vivent les problèmes.
Pour chaque requête d’agent, capturez :
La chaîne de raisonnement complète. Chaque pensée intermédiaire ou étape de planification que l’agent produit. Quand un agent prend une mauvaise décision, la chaîne de raisonnement vous montre où la logique a déraillé. Sans ça, vous devinez.
Les séquences d’appels d’outils avec le chronométrage. Quels outils ont été appelés, dans quel ordre, avec quels paramètres, ce qu’ils ont retourné, et combien de temps chacun a pris. C’est l’artefact de débogage le plus utile pour les systèmes d’agents. Quand vous pouvez voir que l’agent a appelé l’outil de recherche trois fois avec des requêtes presque identiques, le problème est évident. Sans la séquence, vous passeriez des heures à le reproduire.
L’utilisation des jetons par étape. Pas juste le total de jetons par requête. Les jetons consommés à chaque étape de la chaîne de raisonnement. Ça vous dit où le contexte s’accumule et où le coût se concentre.
Les résultats de récupération et scores de pertinence. Si votre agent utilise le RAG, journalisez ce qui a été récupéré et tout score de pertinence ou de similarité. Une mauvaise récupération est la cause première d’un grand pourcentage de défaillances d’agents. Si l’agent reçoit des documents non pertinents, son raisonnement en aval sera faux, peu importe la qualité du modèle.
Les points de décision. Quand l’agent a choisi entre plusieurs options (quel outil appeler, quelle approche prendre, s’il faut demander une clarification), journalisez les alternatives considérées et pourquoi il a fait son choix. C’est la donnée la plus difficile à capturer mais la plus précieuse pour comprendre les biais systématiques dans le comportement de l’agent.
Quels outils d’observabilité fonctionnent le mieux pour les agents IA?
Le paysage des outils d’observabilité pour LLM a mûri rapidement. Voici une évaluation honnête des principales options.
LangSmith fonctionne bien si vous êtes déjà dans l’écosystème LangChain. La visualisation des traces est bonne, et l’intégration demande presque zéro effort si vous utilisez LangChain ou LangGraph. La limitation est le verrouillage fournisseur : si vous vous éloignez de LangChain (et beaucoup de projets d’agents IA personnalisés le font), LangSmith devient plus difficile à justifier. Le prix augmente avec le volume de traces, ce qui devient cher à haut débit.
Langfuse est l’alternative open source qui a gagné en popularité. Vous pouvez l’auto-héberger, ce qui compte pour les équipes avec des exigences de résidence des données ou de sensibilité aux coûts. Le modèle de traçage est agnostique au framework, il fonctionne donc avec des architectures d’agents personnalisées. Le compromis est la surcharge opérationnelle : vous exploitez un service de plus, et la version auto-hébergée nécessite PostgreSQL et de la maintenance.
Arize Phoenix se concentre sur l’évaluation et la détection de dérive. Il excelle pour suivre la qualité des sorties dans le temps et détecter les changements de distribution dans les embeddings ou le comportement du modèle. Moins axé sur le monitoring opérationnel en temps réel, plus sur la compréhension des tendances. Fonctionne bien comme complément à un outil de traçage plutôt qu’en remplacement.
L’instrumentation OpenTelemetry personnalisée est ce sur quoi les équipes avec une infrastructure d’observabilité existante finissent souvent. Vous ajoutez des spans et des attributs à votre pipeline de traçage existant, les envoyez au backend que vous utilisez déjà (Jaeger, Tempo, Honeycomb), et construisez des tableaux de bord dans vos outils existants. L’avantage : pas de nouveau fournisseur et contrôle total. L’inconvénient : un investissement d’ingénierie significatif pour construire les fonctionnalités spécifiques aux LLM (suivi des jetons, rendu de prompts, pipelines d’évaluation) que les outils dédiés incluent nativement.
Pour la plupart des équipes, le chemin pratique est de commencer avec Langfuse ou LangSmith pour le traçage spécifique aux agents et de garder votre stack APM existant pour le monitoring d’infrastructure. Si vous exploitez des systèmes d’agents IA d’entreprise à grande échelle et avez une ingénierie de plateforme solide, l’instrumentation OTel personnalisée offre plus de flexibilité à long terme.

Quelles stratégies d’alerte fonctionnent vraiment pour les agents IA?
L’instinct est de configurer des alertes à seuil sur tout et d’ajuster ensuite. Ça produit de la fatigue d’alertes en une semaine. Les systèmes d’agents sont intrinsèquement variables, et les seuils statiques se déclenchent sur la variance normale.
Commencez avec ces quatre catégories d’alertes :
Seuils durs sur les coûts et les jetons. Fixez un plafond de coût par requête et un plafond de jetons par requête. Ils doivent être assez généreux pour éviter les faux positifs (3 à 5x la médiane) mais assez serrés pour attraper les boucles incontrôlées. Une boucle d’appels d’outils qui brûle 2 $ par requête au lieu des 0,15 $ normaux devrait alerter quelqu’un.
Détection d’anomalies sur la similarité des sorties. Suivez la similarité sémantique des sorties de l’agent pour des entrées similaires dans le temps. Quand les sorties commencent à dériver (scores de similarité plus bas pour des entrées qui devraient produire des réponses cohérentes), quelque chose a changé. Ça attrape la dérive d’hallucination, les mises à jour des fournisseurs de modèles et la dégradation de la qualité de récupération.
Déclencheurs d’escalade pour les actions à faible confiance. Si votre agent peut évaluer sa propre confiance, routez les actions à faible confiance vers une file de révision humaine au lieu de les exécuter. Ce n’est pas techniquement une alerte, mais ça fonctionne comme une : un pic d’escalades de révision humaine vous dit que l’agent a du mal avec une nouvelle classe d’entrées.
Alertes sur le taux de consommation des coûts. Suivez les dépenses horaires et quotidiennes en inférence de modèle. Alertez quand le taux de consommation dépasse 150 % de la moyenne glissante sur 7 jours. Ça attrape à la fois les boucles incontrôlées et les pics de trafic organiques qui pourraient vous faire dépasser le budget avant la fin du mois.
Comment utiliser l’évaluation comme monitoring continu?
La plupart des équipes lancent les évaluations avant le déploiement et s’arrêtent là. Le modèle passe la suite d’évaluation, il est déployé, et personne ne vérifie jusqu’à ce que quelque chose casse. Ça rate la réalité fondamentale des systèmes basés sur les LLM : ils changent sans que vous changiez quoi que ce soit. Les fournisseurs de modèles mettent à jour les poids. La distribution de vos entrées en production évolue. Les documents récupérés deviennent obsolètes.
Lancez votre suite d’évaluation sur le trafic de production en continu. Échantillonnez un pourcentage de requêtes (5 % suffit généralement pour détecter les tendances sans coût significatif), passez-les dans votre pipeline de notation, et suivez les scores dans le temps. La suite d’évaluation que vous avez utilisée avant le déploiement devient un outil de monitoring en production.
Suivez trois choses :
Scores absolus par dimension d’évaluation. Précision, pertinence, sécurité, conformité de format. Ce que vous mesurez avant le déploiement, continuez de le mesurer en production.
Dérive des scores dans le temps. Un déclin graduel dans n’importe quelle dimension est un signal. Configurez des alertes pour des baisses statistiquement significatives sur une fenêtre glissante.
Performance par segment. Les scores agrégés masquent les problèmes. Un agent peut scorer 92 % globalement tout en scorant 65 % sur une catégorie d’entrée spécifique qui représente 8 % du trafic. Décomposez les scores par type d’entrée, segment d’utilisateurs ou catégorie de tâche.
Quand vous exécutez plusieurs versions d’un agent (tests A/B de nouveaux prompts, évaluation d’une mise à jour de modèle), ce pipeline d’évaluation en production vous permet de comparer les versions sur du vrai trafic. Pas des benchmarks synthétiques. Pas des exemples triés sur le volet. De vraies entrées de production avec une signification statistique.
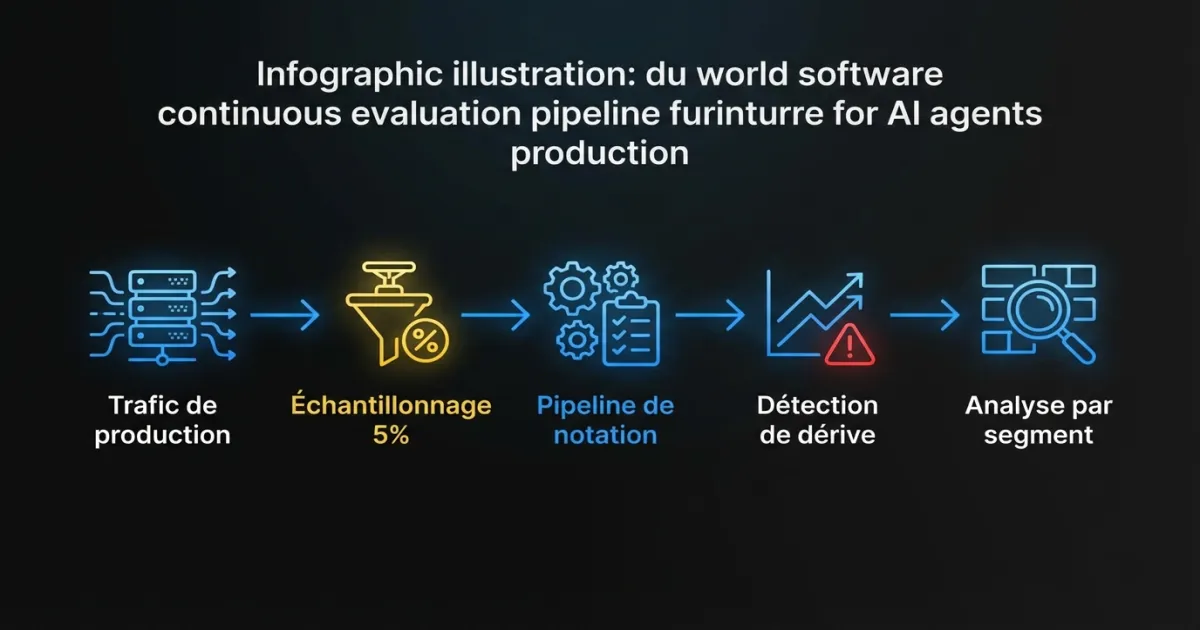
Par où commencer si vous n’avez aucune observabilité d’agent?
Si votre agent est en production aujourd’hui sans observabilité au-delà de l’APM de base, voici trois choses à instrumenter en premier. Elles couvrent les signaux de plus haute valeur avec le moins d’effort.
Premièrement : journalisation requête/réponse avec identifiants de trace. Journalisez l’entrée complète, la sortie et un identifiant de trace unique pour chaque requête d’agent. Stockez-les dans un endroit interrogeable (pas juste un flux de logs). Ça seul vous permet d’investiguer les problèmes signalés par les clients en tirant la requête exacte et en voyant ce que l’agent a fait. Sans ça, vous volez à l’aveugle.
Deuxièmement : taux de succès des appels d’outils et comptages par requête. Instrumentez votre couche d’appels d’outils pour émettre des métriques sur quels outils ont été appelés, s’ils ont réussi, et combien d’appels chaque requête a générés. Ça vous donne un avertissement précoce sur les boucles d’appels d’outils et les défaillances d’intégration. C’est quelques lignes d’instrumentation avec une valeur diagnostique démesurée.
Troisièmement : coût par interaction. Suivez l’utilisation des jetons et le coût estimé de chaque requête. Agrégez par heure et par jour. Configurez une alerte simple si le coût quotidien dépasse 2x la moyenne glissante. C’est la métrique qui attrape la plus grande variété de problèmes : boucles, gonflement du contexte, défaillances de routage de modèle et pics de trafic apparaissent tous dans le coût.
Ces trois éléments vous donnent assez de visibilité pour attraper les modes de défaillance les plus dommageables. Ajoutez la journalisation de la chaîne de raisonnement, l’instrumentation de récupération et l’évaluation continue à mesure que votre pratique d’observabilité mûrit.
Les systèmes d’IA en production échouent différemment du logiciel traditionnel. Plus vite votre monitoring reflète ça, moins vous recevrez de pages à 2h du matin à propos d’un agent qui semblait parfaitement sain tout en donnant de mauvaises réponses aux clients. Les outils et les patrons existent. L’écart est dans l’adoption. La plupart des équipes surveillent encore leurs agents de la même façon qu’elles surveillent des API CRUD. C’est là que le risque se trouve.
FAQ
Quelle est la différence entre l’observabilité des agents IA et l’APM traditionnel?
L’APM traditionnel suit les codes de statut HTTP, la latence et les taux d’erreur. L’observabilité des agents IA ajoute des couches supplémentaires : traçage de la chaîne de raisonnement, journalisation des séquences d’appels d’outils, suivi de l’utilisation des jetons, détection de la dérive d’hallucination et notation de la qualité des sorties. Un agent peut retourner un 200 OK avec une latence parfaite et quand même donner une réponse complètement fausse. L’APM traditionnel ne détectera pas ça.
Combien coûte la mise en place du monitoring des agents IA?
Commencer avec la journalisation basique des requêtes et les métriques d’appels d’outils prend quelques jours d’effort d’ingénierie avec des outils open source comme Langfuse. L’auto-hébergement de Langfuse coûte à peu près la même chose que l’exploitation d’une petite instance PostgreSQL. Les outils SaaS dédiés comme LangSmith facturent au volume de traces, typiquement 0,005 à 0,01 $ par trace. Le coût plus important à considérer est l’évaluation continue, qui nécessite d’échantillonner le trafic de production via un modèle de notation.
Puis-je utiliser mon installation Datadog ou New Relic existante pour les agents IA?
Oui, comme fondation. Gardez votre APM existant pour la santé de l’infrastructure, la disponibilité des API et la performance de base. Puis ajoutez des outils spécifiques aux agents par-dessus pour les traces de raisonnement, le suivi des jetons et la notation de la qualité des sorties. L’instrumentation OpenTelemetry personnalisée peut faire le pont entre les deux, envoyant des spans spécifiques aux agents à votre backend existant tout en ajoutant des attributs spécifiques aux LLM.
Si votre équipe construit ou exploite des agents IA en production et a besoin d’aide pour mettre en place une observabilité qui détecte vraiment les défaillances qui comptent, parlez à notre équipe pour du soutien en ingénierie de la part de gens qui ont construit et exploité ces systèmes à grande échelle.