Point clé
ChatGPT rédige des narratifs RS&DE convaincants, mais échoue au standard de vérification 2026 de l'ARC. Le texte provient d'une invite, pas de votre historique de commits et de vos données source.
La question revient plusieurs fois par semaine sur Google, surtout de la part de directeurs techniques après une réunion où quelqu’un a dit « on n’a qu’à demander à ChatGPT de rédiger les narratifs et économiser les frais du consultant ». C’est une question légitime. ChatGPT produit un narratif technique au format de l’ARC en environ quatre-vingt-dix secondes. La prose est compétente. La structure correspond au formulaire T661. Le résultat semble crédible.
La réponse honnête est non, pas directement. Pas parce que l’IA ne convient pas à la documentation RS&DE, et pas parce que l’ARC l’a interdit (l’ARC ne l’a pas fait). La raison est structurelle. ChatGPT et les autres outils d’IA générative produisent de la documentation qui échoue au test de preuve contemporaine sur lequel repose le processus de vérification 2026 de l’ARC. Le narratif semble correct. Il ne résiste pas à un évaluateur qui demande d’où provient chaque affirmation.
Cet article explique les mécanismes. Si vous évaluez une approche d’IA pour votre réclamation 2026, le traitement approfondi se trouve dans notre guide sur les réclamations RS&DE préparées par IA. Ce qui suit est la réponse directe à la question littérale.
Pourquoi la prose semble-t-elle correcte?
Les grands modèles de langage sont habiles à produire de l’écriture technique plausible. Entraînés sur suffisamment de matériel public, ils ont assimilé la forme d’un narratif RS&DE : une description de projet, une section sur l’incertitude technologique, une section sur l’investigation systématique, une section sur l’avancement, et une conclusion. Fournissez à ChatGPT une invite qui inclut le nom de votre projet et une brève description de ce que votre équipe a construit, et vous obtenez quelque chose qui ressemble à un narratif T661 compétent.
Le résultat est plausible parce qu’il est fluide. Il n’est pas nécessairement exact. Le modèle n’a pas accès à votre base de code. Il n’a pas accès à votre historique de commits, à votre gestionnaire de tickets, ni aux décisions techniques réelles de votre équipe. Il produit un narratif ayant la forme d’un vrai narratif RS&DE, rempli de détails spécifiques qu’il peut deviner à partir de votre invite et de ses données d’entraînement. Certaines suppositions sont correctes. D’autres ne le sont pas.
Ross Pasceri, un comptable de Toronto cité dans un article du Globe and Mail du 16 mars 2026 sur l’IA dans les déclarations fiscales canadiennes, a résumé le problème en une phrase : « la partie la plus effrayante, c’est qu’il semble crédible en surface. » Il parlait d’outils d’IA qui fabriquent des faits fiscaux canadiens. Une augmentation de la limite des gains en capital en 2026 qui n’existe pas dans la législation. Une interprétation technique de l’ARC qui s’est avérée inventée. Le même schéma s’applique aux narratifs RS&DE. Le résultat se lit correctement. Certains détails techniques sont faux.
Pourquoi est-ce un risque plus élevé avec l’ARC en 2026?
Deux changements survenus au début de 2026 rendent les narratifs rédigés par ChatGPT nettement plus risqués qu’ils ne l’auraient été il y a trois ans.
Le premier est le programme d’approbation préalable aux réclamations de l’ARC, entré en vigueur le 1er avril 2026. Ce programme est la nouvelle voie pour confirmer l’admissibilité aux RS&DE avant de produire une déclaration, et il demande une chose précise : de la documentation contemporaine. Cette expression est définie dans les propres documents de l’ARC comme une preuve créée pendant le travail lui-même, pas reconstituée au moment de la déclaration. Un brouillon de ChatGPT est l’opposé définitionnel de contemporain. Le narratif prend naissance au moment de l’invite, des mois ou des années après que le travail a eu lieu.
Le deuxième est que l’ARC utilise maintenant l’IA du côté de la vérification. Le Plan ministériel 2025-26 indique que l’agence « améliore son utilisation de la technologie, notamment l’apprentissage automatique et l’intelligence artificielle, pour détecter la non-conformité et d’autres activités suspectes. » Dans la pratique, pour les évaluateurs RS&DE, cela signifie qu’un écran d’IA tourne sur les narratifs T661 entrants et signale les schémas associés à une documentation de mauvaise qualité ou fabriquée : prose IA générique, absence de liens vers des sources, affirmations sur l’incertitude technologique sans articulation du manque de connaissances sous-jacent.
Un brouillon de ChatGPT déclenche cet écran. La voix est celle du LLM. Le détail technique tend vers le générique parce que le modèle remplit des détails plausibles plutôt que de lire votre dépôt. Le narratif ne sera probablement pas lié à des artefacts datés parce que rien dans l’invite n’a connecté la prose à votre historique git.
Qui est responsable quand l’IA se trompe?
Ryan Minor, directeur des taxes de CPA Canada, a abordé la question de la responsabilité dans le même article du Globe and Mail : « Si une déclaration de revenus contient des erreurs, vous êtes responsable, même si l’IA vous a aidé. » La citation n’est pas spécifique aux RS&DE. Elle s’applique à chaque déclaration fiscale. La chaîne de responsabilité passe par le déclarant.
Concrètement, si ChatGPT invente un détail technique dans votre T661 et que vous le signez, le détail inventé vous appartient. L’ARC ne poursuit pas le LLM. Il n’y a pas de défense procédurale à dire que l’IA a fait l’erreur. Les tribunaux fédéraux ont déjà imposé des sanctions aux avocats qui ont déposé des contenus fabriqués par IA, notamment dans Zhang c. Chen (BCSC, février 2024), une sanction de 5 000 $ dans une affaire au Québec, et une attribution de 500 $ de dépens par la Cour d’appel de l’Alberta avec un avertissement de « pénalités plus substantielles » à l’avenir.
La vérification de l’ARC est administrative, pas contradictoire. Il n’y a pas encore d’analogue aux sanctions des tribunaux. Il y a, cependant, un analogue à l’échec de crédibilité. Un évaluateur qui détecte une fabrication ou une prose IA générique perd confiance dans l’ensemble de la réclamation, pas seulement dans la section signalée.
À quoi ressemble une documentation IA défendable en audit?
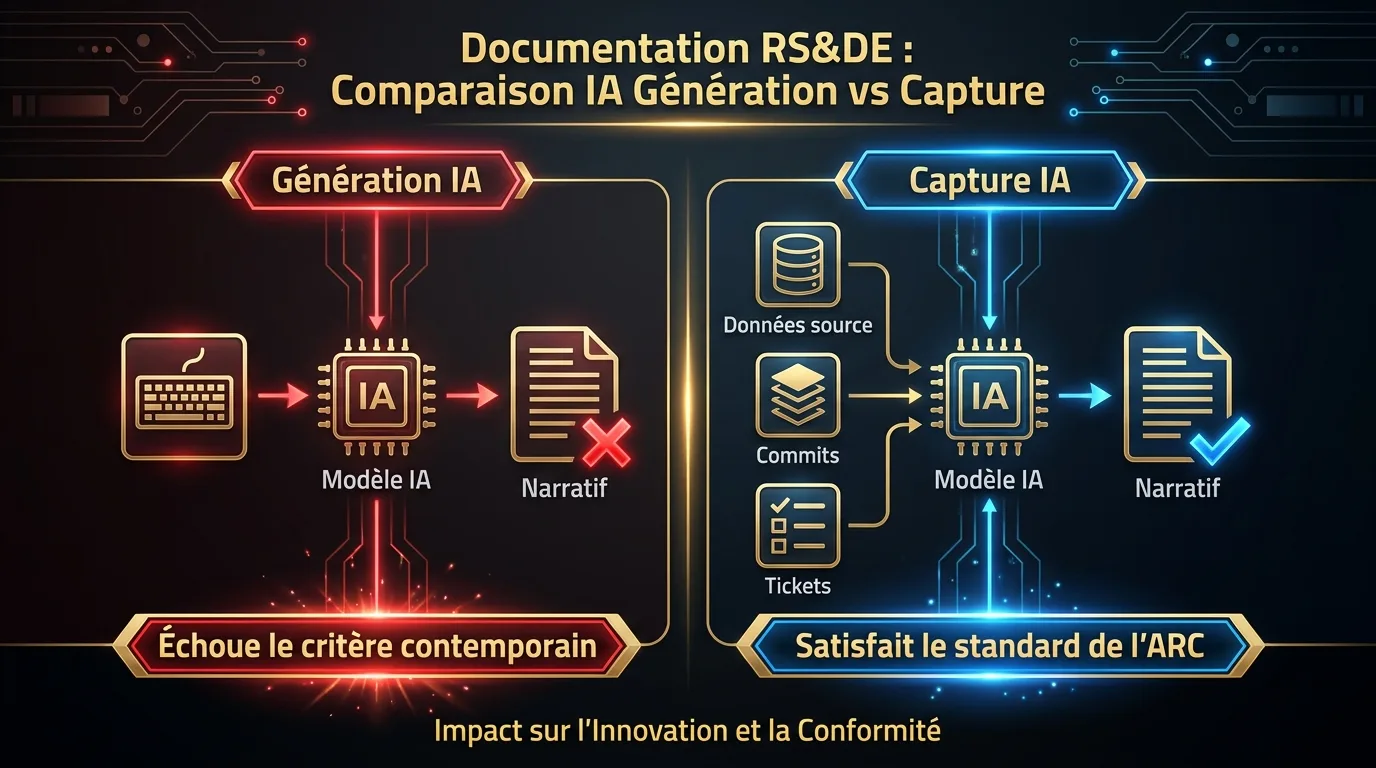
La catégorie « IA pour les RS&DE » n’est pas le problème. L’architecture de la façon dont l’IA est utilisée l’est. Il y a une vraie distinction entre utiliser un modèle génératif pour écrire votre narratif à partir d’une invite et utiliser l’IA pour structurer des preuves de vos données source réelles en catégories alignées sur l’ARC. La première approche est ce que ChatGPT fait par défaut. La seconde est ce que fait un outil basé sur la capture.
Une IA basée sur la capture lit votre historique git, vos pull requests, votre gestionnaire de tickets (Jira, Linear, Asana) et vos messages Slack tagués. Elle ne rédige pas un narratif à partir d’une invite. Elle structure les preuves qui se trouvent déjà dans vos outils dans les catégories que l’ARC valorise : incertitude technologique, investigation systématique, avancement technologique. Le résultat est un brouillon de narratif T661 ancré dans des artefacts source. Chaque ligne renvoie à un commit, un pull request ou un ticket spécifique. Le modèle ne peut pas fabriquer, parce que l’entrée est la donnée source, pas l’invite.
Le site sreducation.ca le dit clairement : « les systèmes qui génèrent des descriptions techniques peuvent produire des déclarations qui semblent plausibles mais ne reflètent pas fidèlement le travail réel, ce qui peut entraîner des réclamations excessives, une mauvaise interprétation des activités du projet, ou l’omission de preuves que l’ARC peut s’attendre à voir. » L’architecture de capture est ce qui évite ce problème.
C’est ce que fait Lucius de Chrono R&D. Comme l’indique un article de BetaKit de janvier 2026, Lucius « ne génèrera pas un rapport prêt à être soumis. Il rédigera plutôt un rapport basé sur les informations qu’il extrait et fournira des espaces réservés aux endroits où il a des questions. » Le brouillon est un artefact structuré, pas un narratif fini. Le relecteur humain prend les décisions. L’IA fait surface les preuves.
Quand est-il acceptable d’utiliser ChatGPT pour les RS&DE?
Il existe une utilisation des outils d’IA génériques qui est raisonnable dans la préparation des RS&DE. ChatGPT, Claude ou Gemini sont des outils raisonnables pour vérifier des définitions, clarifier la terminologie de l’ARC, tester un paragraphe que vous avez vous-même rédigé en demandant au modèle de le critiquer, et convertir la description en langage courant d’un ingénieur en quelque chose de plus aligné sur le cadre d’admissibilité en trois volets de l’ARC, que l’ingénieur peut ensuite vérifier et modifier.
Ce pour quoi ils ne conviennent pas, c’est de produire votre narratif T661 final à partir d’une invite. Le chemin de l’invite au narratif est le chemin qui échoue au standard de vérification 2026. Le modèle ne peut pas lire votre dépôt. Le narratif ne peut pas être lié à des artefacts datés. L’architecture est le problème. Aucune quantité de prompt engineering ou de révision minutieuse de votre côté ne le corrige, parce que les données source ne sont pas l’entrée.
Que devriez-vous faire avant de produire votre déclaration?
Si vous avez déjà rédigé un narratif RS&DE 2026 avec ChatGPT, ne le produisez pas tel quel. Traitez le résultat comme un brouillon structurel et reconstruisez-le à partir de vos données source réelles. Extrayez les commits, les pull requests, les tickets et les notes de conception pour chaque projet. Supprimez la prose du LLM. Rédigez le narratif paragraphe par paragraphe à partir des artefacts. Liez chaque affirmation à une source datée. Faites réviser le dossier par un humain (idéalement un praticien RS&DE certifié) avant de le signer.
Si vous évaluez un outil d’IA pour votre réclamation 2026, posez une question au fournisseur : d’où provient chaque affirmation technique dans le narratif? Un outil basé sur la capture répond avec un hash de commit. Un outil basé sur la génération répond avec une description de l’invite.
Si vous partez de zéro et voulez voir à quoi ressemble la documentation par capture en pratique, notre démo dure vingt-cinq minutes. Nous connecterons Lucius à un dépôt de démonstration et tracerons un paragraphe généré jusqu’au commit d’origine, devant vous.
FAQ
Utiliser ChatGPT pour les RS&DE est-il contraire aux règles de l’ARC?
L’ARC n’a pas interdit les outils d’IA pour la préparation des RS&DE. Le problème est structurel, pas réglementaire. L’IA générative crée des narratifs au moment de la déclaration à partir d’une invite, pas à partir de vos données source. Le standard de vérification 2026 de l’ARC exige une documentation contemporaine, c’est-à-dire des dossiers créés pendant le travail lui-même. Les narratifs rédigés par ChatGPT échouent à ce standard indépendamment de la qualité de la rédaction.
Dans quelles parties de la préparation des RS&DE ChatGPT peut-il légitimement aider?
ChatGPT est utile pour vérifier les définitions de l’ARC, tester des paragraphes que vous avez vous-même rédigés, clarifier la terminologie et convertir les descriptions en langage courant des ingénieurs en cadrage aligné sur l’ARC que l’ingénieur peut ensuite vérifier et modifier. Il ne convient pas à la production du narratif T661 final à partir d’une invite. Les données source doivent guider le narratif.
Que recherche le système de filtrage IA de l’ARC?
Des schémas de prose générique, des liens manquants vers des sources, des affirmations sur l’incertitude technologique sans manques de connaissances articulés, et des narratifs qui pourraient décrire le travail de n’importe quelle entreprise dans le même secteur. La sortie de ChatGPT correspond par défaut à ces quatre schémas, parce que le modèle remplit des détails plausibles plutôt que de lire votre dépôt.
Vous n’êtes pas sûr que votre préparation RS&DE actuelle résistera au standard de vérification 2026 de l’ARC? Parlez à notre équipe. Nous aidons les entreprises logicielles à déterminer si leur documentation est contemporaine, basée sur la capture et prête pour un audit.