Key Takeaway
ChatGPT drafts fluent SR&ED narratives but fails CRA's 2026 audit standard. The prose comes from a prompt, not your actual commit history and source data.
The question gets typed into Google a few times a week, mostly by CTOs after a meeting where someone said “let’s just have ChatGPT draft the narratives and save the consultant fee.” It’s a reasonable thing to wonder. ChatGPT will produce a CRA-style technical narrative in about ninety seconds. The prose is competent. The structure matches the T661 form. The output looks credible.
The honest answer is no, not directly. Not because AI is unfit for SR&ED documentation, and not because CRA has prohibited it (CRA has not). The reason is structural. ChatGPT and other generation-based AI tools produce documentation that fails the contemporaneous-evidence test CRA’s 2026 review process is built around. The narrative looks right. It does not survive a reviewer who asks where each claim came from.
This article explains the mechanics. If you’re evaluating an AI prep approach for your 2026 claim, the deeper treatment is in our cornerstone on AI-prepared SR&ED claims. What follows is the focused answer to the literal question.
Why Does the Prose Look Right?
Large language models are good at producing plausible technical writing. Trained on enough public material, they’ve absorbed the shape of a SR&ED narrative: a project description, a technological uncertainty section, a systematic-investigation section, an advancement section, and a conclusion. Feed ChatGPT a prompt that includes your project name and a brief description of what your team built, and you get back something that reads like a competent T661 narrative.
The output is plausible because it’s fluent. It’s not necessarily accurate. The model has no access to your codebase. It has no access to your commit history, your issue tracker, or your team’s actual technical decisions. It’s producing a narrative shaped like a real SR&ED narrative, populated with whatever specifics it can guess from your prompt and its training data. Some guesses are correct. Some are not.
Ross Pasceri, a Toronto accountant quoted in the Globe and Mail’s March 16, 2026 piece on AI in Canadian tax filings, summarized the failure mode in one sentence: “the scariest part — it looks credible on the surface.” He was talking about AI tools fabricating Canadian tax facts. A 2026 capital gains limit increase that doesn’t exist in legislation. A CRA technical interpretation that turned out to be invented. The same pattern applies to SR&ED narratives. The output reads correctly. Some of the technical details are wrong.
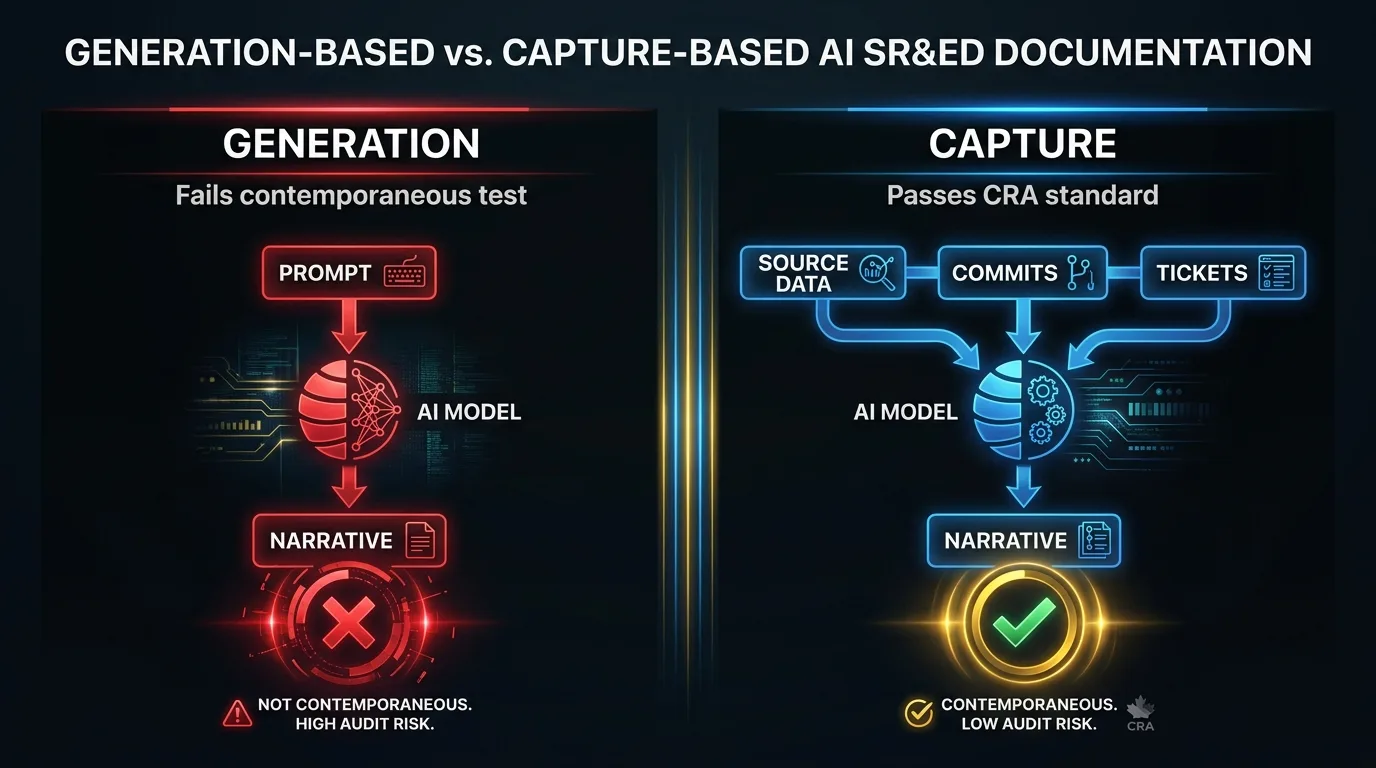
Why Is ChatGPT-Drafted SR&ED Riskier in 2026?
Two things changed in early 2026 that make ChatGPT-drafted narratives substantially more risky than they would have been three years ago.
The first is CRA’s Pre-Claim Approval program, which went live April 1, 2026. Pre-Claim Approval is the new path for confirming SR&ED eligibility before filing, and it asks for one specific thing: contemporaneous documentation. That phrase is defined in CRA’s own materials as evidence created during the work itself, not reconstructed at filing time. A ChatGPT draft is the definitional opposite of contemporaneous. The narrative comes into existence at the moment of the prompt, months or years after the work happened. It does not satisfy the new program’s submission requirement on its face.
The second is that CRA is now running AI on the review side. The 2025-26 Departmental Plan states the agency is “enhancing its use of technology, including machine learning and artificial intelligence (AI), to detect non-compliance and other suspicious activities.” In practice for SR&ED reviewers, that means an AI screen runs on incoming T661 narratives and flags patterns associated with low-quality or fabricated documentation: generic AI prose, claims about technological uncertainty without articulation of the underlying knowledge gap, project descriptions that don’t tie to dated source artifacts, narratives written in the same voice across unrelated companies.
A ChatGPT draft trips that screen. The voice is the LLM’s voice. The technical detail tends toward the generic because the model is filling in plausible specifics rather than reading your repository. The narrative is unlikely to tie to dated artifacts because nothing in the prompt connected the prose to your git history.
Who’s Responsible When AI Gets a Claim Wrong?
CPA Canada’s Director of Tax, Ryan Minor, addressed the responsibility question in the same Globe and Mail piece: “If a tax return contains errors, you’re responsible — even if AI helped you.” The quote is not specific to SR&ED. It applies to every tax filing. The chain of responsibility runs through the filer.
Practically, that means if ChatGPT invents a technical detail in your T661 and you sign it, the invented detail sits with you. CRA does not pursue the LLM. There is no procedural defense in saying the AI made the mistake. Federal courts have already imposed sanctions on lawyers who filed AI-fabricated content, including reprimands in Zhang v. Chen (BCSC, February 2024), a $5,000 sanction in a Quebec case, and a $500 cost award by the Alberta Court of Appeal with a warning of “more substantial penalties” going forward. The Federal Court Practice Direction of May 7, 2024 mandates AI-use disclosure in any submission.
CRA review is administrative, not adversarial. There’s no analog to a court sanction yet. There is, however, an analog to the credibility failure. A reviewer who detects fabrication or generic AI prose loses confidence in the entire claim, not just the flagged section.
What Does Audit-Defensible AI Documentation Look Like Instead?
The category of “AI for SR&ED” is not the problem. The architecture of how AI is used is the problem. There’s a real distinction between using a generative model to write your narrative from a prompt and using AI to structure evidence from your real source data into CRA-aligned categories. The first is what ChatGPT does by default. The second is what a capture-based tool does.
A capture-based AI reads your git history, your pull requests, your issue tracker (Jira, Linear, Asana), and your tagged Slack messages. It does not write a narrative from a prompt. It structures the evidence that’s already in your tools into the categories CRA cares about: technological uncertainty, systematic investigation, technological advancement. The output is a draft T661 narrative grounded in source artifacts. Each line ties back to a specific commit, pull request, or ticket. The model cannot fabricate, because the input is the source data, not the prompt.
The education hub sreducation.ca puts the distinction clearly: “systems that generate technical descriptions may produce statements that sound plausible but do not accurately reflect the real work, which can lead to over-claiming, misinterpretation of project activities, or the omission of evidence that the CRA may expect to see.” The capture architecture is what avoids that failure mode.
This is what Chrono R&D’s Lucius does. To quote a January 2026 BetaKit piece: Lucius “will not generate a report that is ready for submission. Instead, it will draft a report based on the information it extracts and provide placeholders in spots where it has questions.” The draft is a structured artifact, not a finished narrative. The human reviewer makes the judgment calls. The AI surfaces evidence.
When Is It Actually OK to Use ChatGPT for SR&ED?
There is a use of generic AI tools that’s reasonable in SR&ED prep. ChatGPT, Claude, or Gemini are reasonable tools for spot-checking definitions, clarifying CRA terminology, stress-testing a paragraph you wrote yourself by asking the model to critique it, and converting an engineer’s plain-language description of a problem into something more closely aligned with CRA’s three-part eligibility framework, which the engineer can then verify and edit.
What they’re not fit for is producing your final T661 narrative from a prompt. The prompt-to-narrative path is the path that fails the 2026 review standard. The model cannot read your repository. The narrative cannot tie to dated source artifacts. The architecture is the failure mode. No amount of prompt engineering or careful review fixes it, because the source data is not the input.
What Should You Do Before Filing?
If you’ve already drafted a 2026 SR&ED narrative with ChatGPT, don’t file it as written. Treat the output as a structural draft and rebuild it from your actual source data. Pull the commits, pull requests, tickets, and design notes for each project. Strip the LLM prose. Write the narrative paragraph by paragraph from the artifacts. Tie every claim to a dated source. Have a human (ideally a certified SR&ED practitioner) review the file before you sign.
If you’re evaluating an AI prep tool for your 2026 claim, ask the vendor one question: where does every technical claim in the narrative come from? A capture-based tool answers with a commit hash. A generation-based tool answers with a description of the prompt.
If you’re starting from scratch and want to see what capture-based documentation looks like in practice, our demo is twenty-five minutes. We’ll connect Lucius to a sample repository and trace a generated paragraph back to the commit it came from, in front of you. The trace is the product. Either it works or it doesn’t.
FAQ
Is using ChatGPT for SR&ED against CRA rules?
CRA has not prohibited AI tools for SR&ED prep. The problem is structural, not regulatory. Generation-based AI creates narratives at filing time from a prompt, not from your source data. CRA’s 2026 review standard requires contemporaneous documentation, meaning records created during the work itself. ChatGPT-drafted narratives fail that standard regardless of how well they’re written, because they are definitionally not contemporaneous.
What parts of SR&ED prep can ChatGPT legitimately help with?
ChatGPT is useful for spot-checking CRA definitions, stress-testing paragraphs you wrote yourself, clarifying terminology, and converting plain-language engineer descriptions into CRA-aligned framing that the engineer can then verify and edit. It’s not fit for producing the final T661 narrative from a prompt. The source data must drive the narrative, not the other way around.
What does CRA’s AI screening system actually look for?
Generic prose patterns, missing source linkage, technological-uncertainty claims without articulated knowledge gaps, and narratives that could describe work at any company in the same vertical. ChatGPT output matches all four patterns by default because the model fills in plausible specifics rather than reading your repository. The AI-assisted SR&ED audit defense article covers what distinguishes capture-based output from generation-based output in detail.
Not sure whether your current SR&ED prep will hold up under CRA’s 2026 review standard? Talk to our team. We help software companies identify whether their documentation is contemporaneous, capture-based, and audit-ready.