Key Takeaway
CRA approves AI/ML SR&ED claims when you prove known methods failed, document a structured investigation, and show what new knowledge resulted.
Every software company building with AI faces the same question at tax time: does our work qualify for SR&ED?
CRA has noticed the surge. AI/ML claims jumped roughly 40% year-over-year since 2023. In response, CRA Science Advisors sharpened their review criteria. Internal guidance documents circulated in early 2026 specifically address how to evaluate machine learning claims. The bar hasn’t changed in principle. But the way reviewers apply it to AI/ML work is more precise now, and less forgiving of vague filings.
This article covers where the eligibility line sits for the most common AI/ML work categories: training data curation, prompt engineering, model fine-tuning, novel architecture development, and MLOps.
What’s the Difference Between “Using AI” and “Advancing AI”?
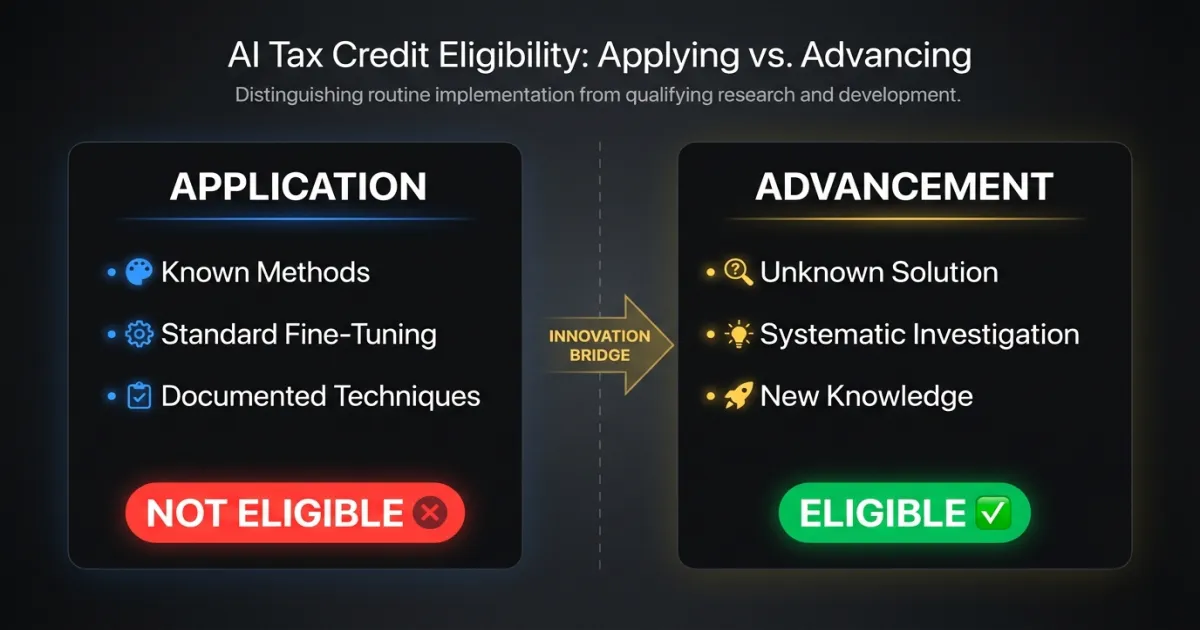
CRA’s three-part eligibility test applies to AI/ML the same way it applies to any other technology. The work must involve technological uncertainty, systematic investigation, and technological advancement.
The problem: most AI/ML work at software companies falls into application, not advancement. Your team fine-tuned a language model to extract contract clauses. That’s impressive engineering. But unless the fine-tuning process itself required solving a problem that wasn’t addressable through known techniques, it’s application of existing technology.
CRA reviewers now distinguish clearly between two categories.
Application of AI/ML means using established models, techniques, and workflows to solve a business problem. Training a classifier on labeled data using standard architectures. Fine-tuning an LLM with well-documented methods. Deploying a model with standard MLOps pipelines. None of this qualifies on its own.
Advancement of AI/ML means encountering a technical problem where known methods were insufficient, investigating alternative approaches systematically, and producing new knowledge about what works and why. This can qualify.
The distinction isn’t about how difficult the work was. It’s about whether the solution was knowable before you started.
Does Training Data Curation Qualify for SR&ED?
Rarely on its own. CRA’s updated guidance is direct: collecting, cleaning, labeling, and organizing training data is not eligible unless the curation process itself required solving a technological uncertainty.
What doesn’t qualify
- Building a data pipeline to ingest and normalize documents from multiple sources
- Manual or semi-automated labeling of training examples
- Standard data augmentation techniques (rotation, cropping, synonym replacement)
- Writing validation rules to filter low-quality samples
All of this is standard practice. A competent data engineer applying known methods can execute it.
What can qualify
- Developing a novel active learning approach because labeling budgets couldn’t support the volume required, and existing methods produced unacceptable selection bias for your data distribution
- Investigating whether synthetic data generation could replace real-world samples in a domain where no prior research existed on synthetic-to-real transfer
- Creating a new debiasing methodology where standard techniques (resampling, reweighting) failed to address intersectional bias patterns specific to your domain
The qualifying factor is always the same: a known technique was insufficient, your team investigated alternatives through structured experimentation, and the investigation produced knowledge that didn’t exist before.
Does Prompt Engineering Qualify for SR&ED?
Almost never. This category draws the most CRA rejections in 2026.
Writing prompts, testing variations, evaluating outputs, and iterating on phrasing is an optimization process using a known tool. The LLM’s behavior is the vendor’s technology. Figuring out how to get better results from it is application, not research.
What doesn’t qualify
- Iterating on system prompts to improve response accuracy
- Developing prompt templates for specific use cases
- Testing chain-of-thought vs. few-shot approaches for a particular task
- Building evaluation frameworks to score prompt effectiveness
The narrow exception
Prompt engineering can contribute to a qualifying claim when it’s part of a larger investigation into genuine technological uncertainty. Example: your team researches whether LLMs can perform reliable causal reasoning in a specific technical domain, and prompt variations are one experimental variable among several (model architecture, fine-tuning approach, retrieval strategy). The prompt work supports the investigation. It isn’t the investigation itself.
Even then, the prompt engineering hours alone don’t qualify. They’re supporting work within a broader eligible project.
When Does Fine-Tuning Cross Into SR&ED Territory?
Fine-tuning is the grey zone where most AI/ML SR&ED disputes happen. CRA’s position has become more nuanced in 2026.
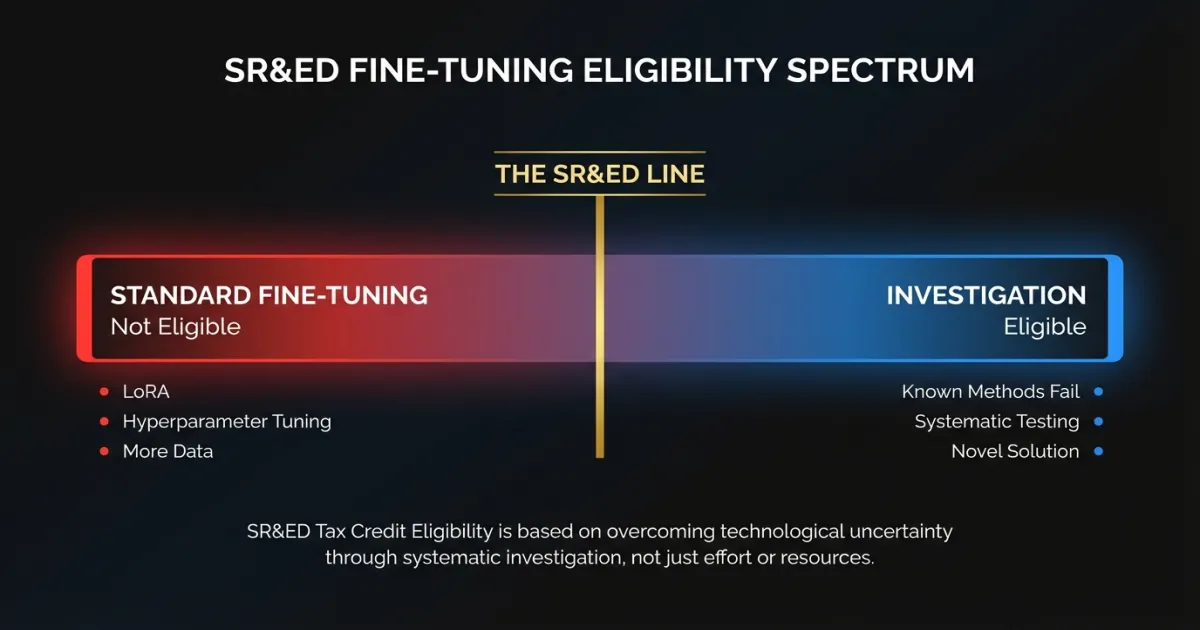
Standard fine-tuning: does not qualify
Taking a pre-trained model, preparing a domain-specific dataset, and fine-tuning with established methods (LoRA, QLoRA, standard supervised fine-tuning) is applied engineering. The techniques are documented. The process is well understood. A qualified ML engineer following published guides can execute it.
This is true even if the results are impressive. CRA doesn’t evaluate whether the output is valuable. They evaluate whether the process required solving an unknown.
Fine-tuning that qualifies
The work crosses into SR&ED territory when standard approaches fail and your team must investigate why.
Example that qualifies: Your team fine-tuned a 7B parameter model for medical document classification. Standard LoRA achieved 72% accuracy, well below the 95% clinical threshold. Your team hypothesized the failure stemmed from the model’s inability to maintain context across multi-page documents. You systematically tested five approaches: modified attention windowing, hierarchical chunking with cross-chunk attention, a two-stage retrieval-then-classify pipeline, custom positional encoding modifications, and an ensemble of specialized sub-models. Three approaches failed. The fourth degraded short-document performance. The fifth, requiring a novel combination of hierarchical chunking with custom cross-attention not described in existing literature, achieved 96%. Each experiment was documented with hypotheses, configurations, results, and technical reasoning.
That qualifies. The technological uncertainty was real. The investigation was systematic. The result advanced the state of the art for that problem class.
Example that doesn’t qualify: Your team fine-tuned the same model for support ticket classification. Standard LoRA achieved 89%. You wanted 93%. You tried hyperparameter tuning, added more training data, and adjusted learning rate schedules. After several iterations, you reached 92.5%.
That’s optimization, not research. The techniques were standard. The uncertainty was about degree of performance, not whether the approach would work.
Novel architecture work
Building genuinely new model architectures almost always qualifies, because by definition you’re creating something absent from published literature. But CRA reviewers will verify the novelty is real. If your “novel architecture” is a standard transformer with a modified attention head, they’ll check whether that specific modification was already described in papers or open-source implementations.
How Does System-Level Uncertainty Strengthen AI/ML Claims?
One area where CRA’s 2026 guidance actually helps claimants: system-level uncertainty. This matters for AI/ML companies.
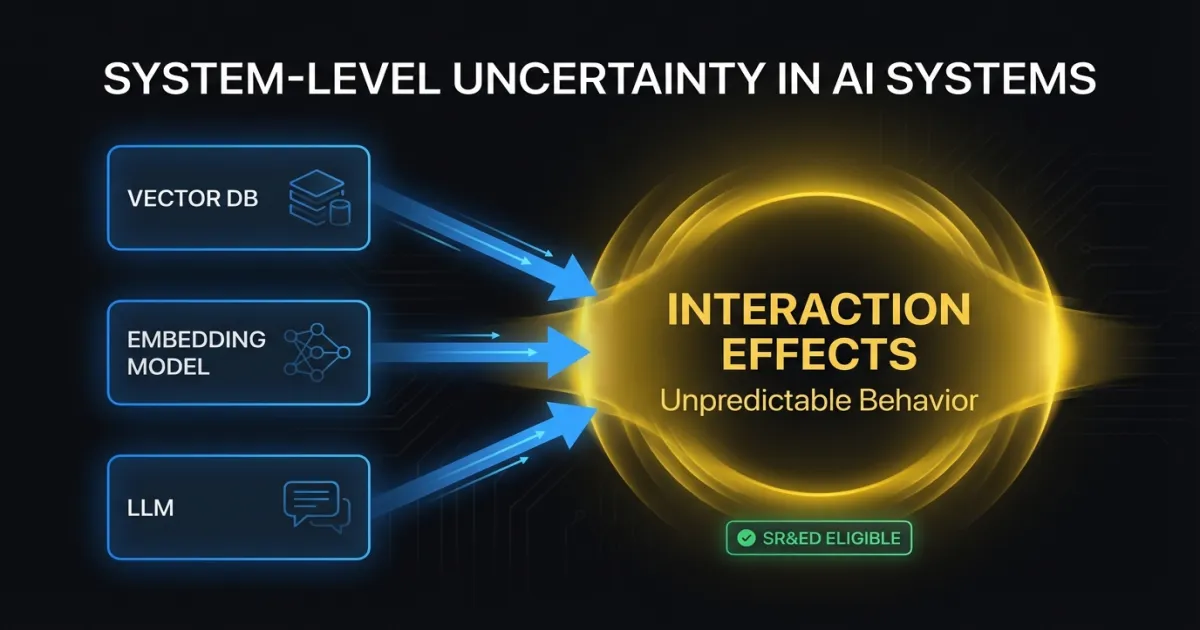
A 2024 Tax Court decision confirmed that combining known components can create genuine technological uncertainty when their interactions produce unpredictable behavior. CRA’s updated internal guidance extends this to AI/ML systems explicitly.
If your team combined a known retrieval system with a known LLM and a known re-ranking model, and the interaction between these components produced failure modes that none of the individual documentation predicted, the investigation into those interaction effects can qualify.
Concrete example: Your team built a RAG system using an established vector database, a standard embedding model, and a commercial LLM. Each component performed as documented individually. Combined, the system exhibited hallucination patterns that didn’t occur with the LLM alone. Your team discovered the retrieval component was surfacing semantically similar but factually contradictory passages. The LLM’s behavior when given contradictory context wasn’t described in any published research. The systematic investigation into this interaction, and the novel resolution your team developed, qualifies as SR&ED.
System-level uncertainty is one of the strongest claim angles for AI/ML companies. Modern AI applications are almost always systems of interacting components. Document the interactions, not just the individual pieces.
Does MLOps Work Qualify for SR&ED?
CRA treats MLOps the same way they treat DevOps and infrastructure work: the ops itself doesn’t qualify, but solving novel technical problems within it can.
What doesn’t qualify
- Building CI/CD pipelines for model deployment
- Implementing standard model monitoring (drift detection, performance dashboards)
- Setting up A/B testing infrastructure for model variants
- Container orchestration for model serving
- Standard feature stores and feature engineering pipelines
What can qualify
- Investigating a novel approach to real-time model retraining because existing incremental learning methods couldn’t handle your data’s non-stationary distribution without catastrophic forgetting
- Developing a new method for detecting concept drift in multi-modal models where standard statistical tests produced unacceptable false positive rates
- Researching techniques for maintaining model consistency across distributed serving where network partitions caused divergent model states that existing consensus protocols couldn’t resolve
The pattern holds: known techniques applied to new situations is engineering. Known techniques failing in new situations, followed by systematic investigation into alternatives, is where SR&ED begins.
What Documentation Survives CRA Review?
AI/ML claims require documentation beyond what most teams produce naturally. CRA reviewers evaluating ML projects look for specific evidence. For a detailed walkthrough of SR&ED technical narratives and what CRA expects in each T661 section, see our dedicated guide.
What reviewers want to see
Baseline measurements. Before you claim standard methods failed, show that you tried them and recorded results. “We knew LoRA wouldn’t work” is not technological uncertainty. “We applied LoRA using recommended hyperparameters and achieved 72% accuracy against a 95% requirement” is.
Experiment logs with specific metrics. Each approach tested should have documented inputs, configurations, outputs, and quantitative results. Git commits with timestamps help. Experiment tracking tools (Weights & Biases, MLflow, Neptune) produce exactly the records CRA values.
Clear articulation of what was unknown. The T661 narrative must explain what your team didn’t know and why that gap couldn’t be closed through existing knowledge. For AI/ML work, this often means citing specific papers or techniques you evaluated and explaining why they were insufficient.
Literature review evidence. CRA reviewers increasingly expect AI/ML claimants to demonstrate they searched existing research before concluding a technological uncertainty existed. If a solution was published in a 2024 arXiv paper your team didn’t find, that weakens the claim. Keep records of literature searches your team conducted.
Separation of qualifying and non-qualifying work. Within an AI/ML project, some work qualifies and some doesn’t. Your data pipeline buildout probably doesn’t. Your investigation into why standard architectures failed on your data probably does. CRA expects clear separation with time allocation for each. See our guide to SR&ED eligible activities for where these lines typically fall.
How Should You Structure AI/ML Work for Defensible Claims?
If your company does genuine AI/ML research as part of product development, how you structure and document that work determines whether your claim survives review.
Separate research spikes from production engineering. When your team encounters a problem where known approaches fail, create a distinct work stream for the investigation. This makes it straightforward to identify qualifying hours and activities. Mixing research and routine development in the same tickets makes CRA’s job harder. They tend to resolve ambiguity against the claimant.
Document the failure of known methods first. Before investigating alternatives, record that you tried the standard approach and it didn’t work. Include specific metrics. This is the foundation of your technological uncertainty claim.
Keep experiment records granular. Every approach tested should have its own documentation: the hypothesis, the method, the configuration, the result, and the conclusion. Experiment tracking platforms generate this automatically. If your team doesn’t use one, start.
Write technical narratives as you go. Waiting until claim time to reconstruct reasoning behind six months of ML experiments is how claims get weak. Engineers forget why they abandoned approach B. They can’t remember specific metrics from the third experiment. Monthly or quarterly narrative drafts, even rough ones, preserve the detail that makes claims defensible.
Know the boundary before you start. Not every hard ML problem is an SR&ED problem. Before allocating significant effort to a technical challenge, ask: could a qualified practitioner solve this by applying known techniques? If yes, it’s engineering. If no, and you can articulate why, you may have a qualifying project. Making this assessment early, and documenting it, strengthens the claim.
For real-world SR&ED examples across different types of software R&D, including AI/ML projects, see our examples library. If you’re concerned about a potential SR&ED audit, understanding CRA’s review process before filing is always better than learning about it after.
FAQ
Is all AI/ML work eligible for SR&ED tax credits?
No. Most AI/ML work at software companies is application of existing technology, not advancement. Using established models, fine-tuning with documented methods, and deploying with standard pipelines doesn’t qualify. Work qualifies only when known techniques fail, you investigate alternatives systematically, and produce new technical knowledge.
Why is CRA rejecting so many prompt engineering claims?
Prompt engineering is optimization using a known tool. Writing, testing, and iterating on prompts is an engineering process, not a research activity. CRA treats it the same as tuning configuration parameters. It can support a broader qualifying project, but it doesn’t create SR&ED eligibility on its own.
What’s the strongest SR&ED claim angle for AI/ML companies?
System-level uncertainty. CRA’s 2026 guidance and a 2024 Tax Court decision both recognize that combining known components can create genuine technological uncertainty when their interactions produce unpredictable behavior. Most modern AI applications are systems of interacting components, making this a natural and defensible claim angle.
Not sure where your AI/ML work falls on the eligibility line? Talk to our SR&ED team. We help software companies identify qualifying R&D, structure documentation that survives CRA review, and maximize claims without overreaching.