The demo looked amazing. Your team built an AI assistant in two weeks. It answered questions about your product, summarized documents, and even handled multi-step workflows. Leadership was thrilled. Customers in the pilot loved it.
Six months later, the project is dead.
If this sounds familiar, you’re not alone. According to MIT’s 2025 research on the GenAI divide, 95% of AI pilots fail to deliver ROI. McKinsey’s 2025 analysis found that most companies using AI see no financial benefit. The gap between “the demo works” and “the product works” is where projects go to die.
Growing companies are building AI products faster than ever. LLM APIs from OpenAI, Anthropic, and others have democratized access to powerful language models. What once required a team of ML engineers can now be prototyped by a single developer in an afternoon. But this ease of starting creates a dangerous illusion: if it’s this easy to build a demo, shipping to production must be just as straightforward.
It isn’t. The “it works on my laptop” to “it works in production” gap is wider for AI products than anything we’ve seen in software development. And the failure patterns are different from traditional software failures.
The New Failure Patterns
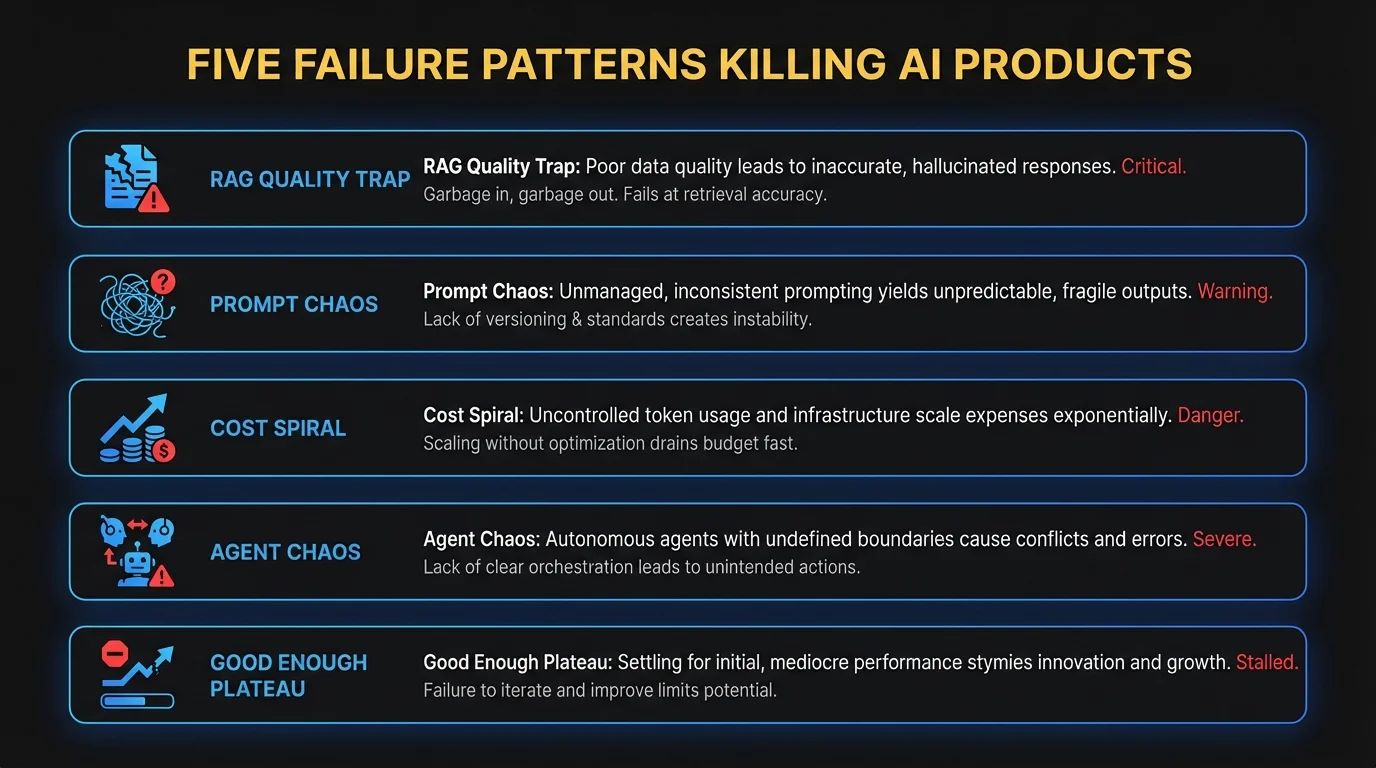
If you’re building products powered by LLMs, RAG systems, or AI agents, you’ll recognize these patterns. They’re not about model training or GPU clusters. They’re about the unglamorous work of shipping reliable AI products to real users.
Pattern 1: The RAG Quality Trap
Retrieval-Augmented Generation seemed like the perfect solution. Instead of fine-tuning models or hoping for accurate responses from general knowledge, you’d ground the AI in your actual data. Your documentation, your knowledge base, your customer records.
In testing, it worked beautifully. The model retrieved relevant chunks and synthesized accurate answers. Then real users showed up.
The queries your test set included were nothing like the questions customers actually asked. Your chunking strategy—which seemed perfectly reasonable when you set it up—started returning garbage. Documents that should have been retrieved weren’t. Documents that shouldn’t have been retrieved were. The model confidently presented wrong information as fact.
Users got incorrect answers. Some noticed and complained. Others didn’t notice and made decisions based on bad information. Trust eroded fast. By the time you identified the retrieval problems, your AI assistant had a reputation for being unreliable.
The trap is that RAG quality is invisible until it fails. Your retrieval pipeline doesn’t throw errors when it returns the wrong documents. It just quietly degrades the user experience.
Pattern 2: Prompt Chaos
You started with one prompt. It was elegant. It worked. Then edge cases appeared.
Users asked questions in unexpected ways. The model hallucinated on certain topics. Responses were too long, then too short, then formatted wrong. Each problem got a prompt tweak. Each tweak introduced new problems.
Now you have 47 prompt variations across your codebase. Some are in configuration files. Some are hardcoded. Some are in a database that someone set up for “prompt management” before they left the company. Nobody knows which prompt is actually running in production. There’s no versioning, no testing framework, no way to roll back when a “quick fix” breaks something else.
One developer makes an innocent change to improve response formatting. Customer support tickets spike. Nobody connects the two events for three days.
Prompt engineering isn’t engineering when there’s no discipline around it. It’s chaos with a fancy name.
Pattern 3: The Cost Spiral
The proof of concept cost $200 a month in API calls. Totally reasonable. Leadership approved the production budget based on this number.
Launch day hit $2,000. Marketing did a push, and suddenly you had real users. Month three reached $15,000 and climbing. Finance started asking questions.
The problem wasn’t that anyone did anything wrong. The problem was that AI products have a cost model unlike traditional software. Your infrastructure costs don’t scale linearly with users—your per-request costs scale with usage and complexity.
No caching meant identical questions generated new API calls every time. No optimization meant every request used the most expensive model, even for simple queries. No budget controls meant there was no circuit breaker when costs spiked.
Your product is one viral moment away from a budget crisis. A single power user discovered they could use your AI assistant for tasks you never intended, and their usage alone costs more than your original monthly budget.
Pattern 4: Agent Chaos
Agents were the exciting part. Instead of just answering questions, your AI could take actions. Book appointments. Update records. Send emails. The demo was impressive—a multi-step workflow completed automatically, with the agent reasoning through each step.
In production, things got weird.
The agent entered loops, calling the same tool repeatedly until rate limits kicked in. It made wrong tool calls based on misunderstood user intent. It hallucinated actions that seemed plausible but weren’t what the user wanted. It took irreversible actions that couldn’t be undone.
There was no logging comprehensive enough to understand what went wrong. No human oversight for risky actions. No graceful degradation when the agent got confused. Users triggered edge cases your test suite never imagined.
Anthropic’s research on building effective agents emphasizes that agents need careful guardrails and human oversight. Most teams learn this lesson the hard way.
Pattern 5: The “Good Enough” Plateau
Your AI product reached 80% accuracy. For a while, that seemed fine. Better than nothing, right? Better than the manual process it replaced.
But that 20% failure rate destroys user trust faster than you’d expect. Users don’t experience aggregate accuracy. They experience individual interactions. Every wrong answer, every confused response, every hallucination is a moment where your product failed them specifically.
Worse, there’s no feedback loop. Users who get wrong answers often don’t report them—they just stop using the product. You have no systematic way to identify failures, categorize them, or improve. The product sits at 80% accuracy while competitors iterate their way to 90%, then 95%.
The plateau isn’t a resting point. It’s where products go to slowly become irrelevant.
Why LLM Products Are Harder Than They Look
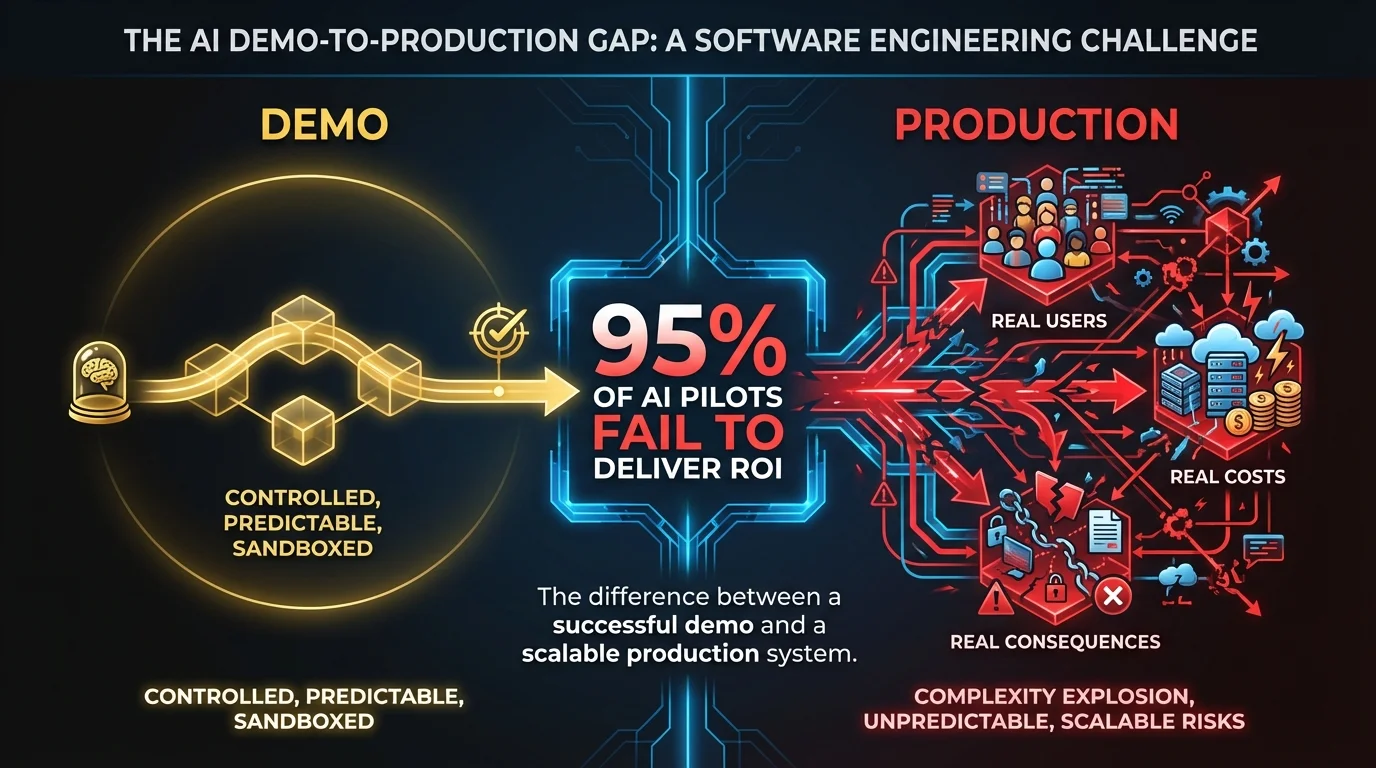
These patterns share a common root cause: LLM-powered products have fundamentally different characteristics than traditional software, but teams try to build them the same way.
APIs make starting easy, finishing hard. The same accessibility that lets you build a demo in a day means you skip the hard thinking about architecture, testing, and operations. By the time you realize you need that foundation, you’re already in production with users depending on a fragile system.
Non-deterministic outputs need different testing. Traditional software testing verifies that given input X, you get output Y. LLM outputs vary. The same input might produce different outputs. “Correct” is often subjective. Your test suite from traditional software development doesn’t transfer.
Costs scale with usage in new ways. Traditional SaaS might have higher infrastructure costs at scale, but they’re predictable and usually decreasing per-unit. LLM costs are per-request and can spike unpredictably based on user behavior you don’t control.
User expectations are sky-high. ChatGPT trained users to expect AI that’s conversational, capable, and reliable. Your product is compared to that benchmark, even if your use case is narrower and your resources are smaller.
What Successful AI Products Do Differently
The companies that ship AI products successfully aren’t using magic. They’re applying discipline that most teams skip in the rush to launch.
Build cost controls from day one. Implement caching for common queries. Use cheaper models for simple tasks and reserve expensive models for complex ones. Set budget alerts and automatic throttling. Know your cost per user before you have too many users.
Implement human-in-the-loop for risky actions. Don’t let your agent take irreversible actions without human approval. Design escalation paths for uncertain situations. Make it easy for users to correct mistakes before they compound.
Version and test prompts like code. Store prompts in version control. Write tests that verify prompt changes don’t break existing functionality. Have a rollback plan for every prompt deployment. Treat prompt engineering with the same rigor as software engineering.
Design for the 20% failure case. Assume your AI will be wrong sometimes. Build graceful degradation. Make it easy for users to report problems. Design UX that doesn’t promise perfection.
Collect feedback and actually use it. Instrument your product to capture when users abandon sessions, retry queries, or express frustration. Build a pipeline to review failures regularly. Make improvement systematic, not reactive.
The Mid-Market Advantage
If you’re at a growing company—not a giant enterprise, not a tiny startup—you have advantages that can help you ship where others fail.
Faster decisions. You don’t need six months of committee meetings to change your approach. When something isn’t working, you can pivot quickly.
Less legacy to integrate with. Enterprises struggle to connect AI products to decades of accumulated technical debt. Your systems are newer and more flexible.
Incremental shipping. You can launch to a subset of users, learn, and iterate. You don’t need a big-bang release that works perfectly for everyone on day one.
User forgiveness. Your customers chose a growing company for a reason. They expect iteration and improvement. They’ll give you feedback instead of just churning—if you listen.
These advantages only matter if you use them. The companies that ship AI products successfully treat the first version as the beginning, not the end.
Moving Forward
The 95% failure rate for AI pilots isn’t inevitable. It reflects the gap between how easy it is to start and how hard it is to finish. Closing that gap requires treating AI products with the same operational rigor as any other production system—plus the additional discipline that non-deterministic, pay-per-use technology demands.
The opportunity is real. Companies that figure out how to ship AI products reliably will have significant advantages over those still stuck in pilot purgatory. The question isn’t whether AI products are worth building. It’s whether you’ll build them in a way that actually ships.
The demo was the easy part. Now the real work begins.
Ready to ship your AI product? We’ve compiled an AI Production Readiness Checklist covering the 20 critical items to verify before your AI product goes live—including RAG quality, prompt management, cost controls, agent safety, and team readiness. Contact us to learn how Chrono Innovation can help you move from pilot to production.