Tous les diagrammes d’architecture d’agents IA qu’on trouve en ligne montrent la meme chose. Un LLM au centre. Des fleches vers des outils. Un stockage memoire sur le cote. Une boucle propre : l’utilisateur envoie un message, l’agent raisonne, appelle un outil, obtient un resultat, repond. Termine.
Ce diagramme couvre environ 10 % de ce qu’un systeme d’agent en production fait reellement.
Les 90 % restants, c’est le travail que personne ne dessine au tableau blanc. Gerer les defaillances partielles en cours d’execution. Maintenir l’etat entre des sessions qui durent des heures. Retracer pourquoi un agent a choisi l’Outil A plutot que l’Outil B dans une chaine de quinze decisions. Recuperer quand l’API tierce retourne un 500 a l’etape 11 sur 14. C’est ca, la vraie architecture. L’architecture ennuyeuse, critique, celle qui maintient votre systeme a 3 h du matin.
L’ecart entre un agent de demo et un agent en production ne tient pas a des prompts plus intelligents ou de meilleurs modeles. Il se resume a trois choses : la gestion des erreurs, l’observabilite et la gestion d’etat. Les equipes qui comprennent ca livrent des agents fiables. Les autres construisent des demos qui cassent sous la charge.
La boucle de base est simple. Tout le reste ne l’est pas.
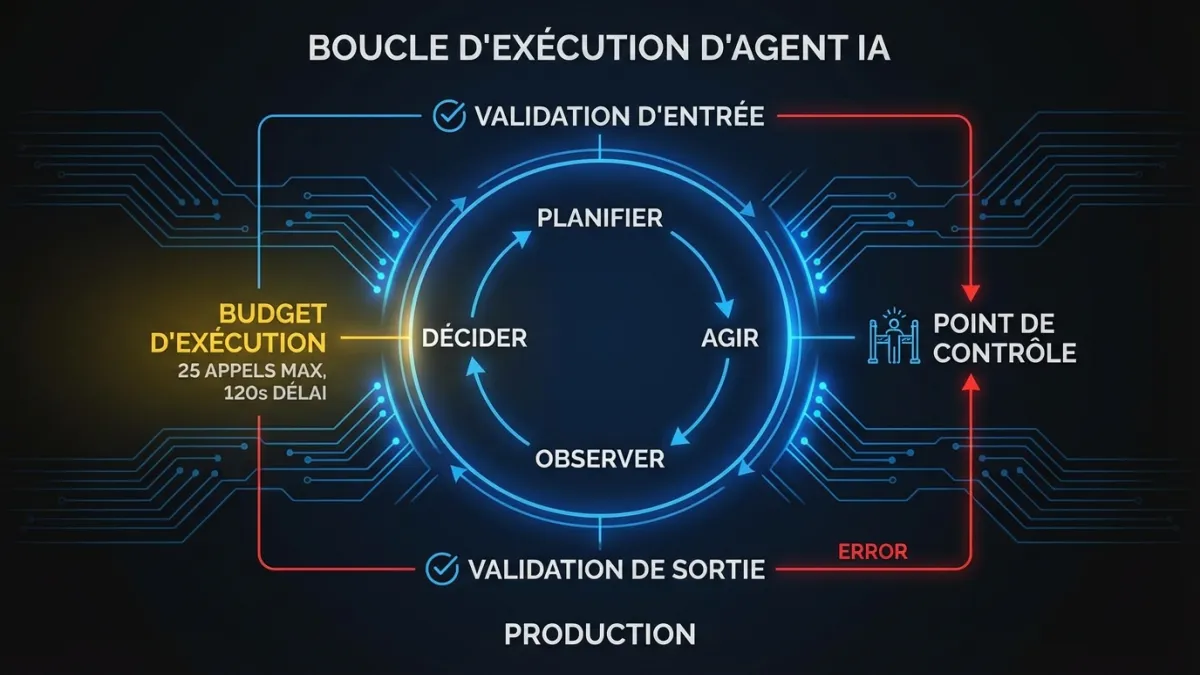
La boucle d’execution de base d’un agent est bien comprise. Planifier, agir, observer, decider. Le LLM recoit du contexte, choisit une action (generalement un appel d’outil), observe le resultat et decide de continuer ou de repondre. ReAct, function calling, tool use. Des noms differents pour le meme patron. Si vous voulez les fondamentaux, notre guide du constructeur sur l’IA agentique couvre les concepts de base.
Les systemes de production enveloppent cette boucle dans des couches d’infrastructure qui gerent tout ce que la boucle ignore.
La validation des entrees se fait avant que le LLM ne voie la requete. L’utilisateur est-il authentifie ? Sa session a-t-elle les bonnes permissions pour les outils de cet agent ? Les tokens d’entree sont-ils dans le budget pour ce niveau de requete ?
La validation des sorties se fait apres chaque appel d’outil et chaque reponse du LLM. Le modele a-t-il retourne du JSON valide la ou du JSON etait attendu ? La sortie structuree correspond-elle au schema ? Y a-t-il des valeurs hallucinees qui corrompraient les donnees en aval ?
Les budgets d’execution plafonnent le nombre d’etapes que l’agent peut prendre, les tokens qu’il peut consommer et sa duree d’execution. Sans ca, un agent confus boucle indefiniment, brulant des tokens et du calcul sans rien accomplir. Nous fixons des limites strictes : maximum 25 appels d’outils par execution, 120 secondes de temps reel, 50 000 tokens de sortie. Les chiffres exacts dependent du cas d’usage, mais le principe est non negociable. Chaque agent a un budget.
Patrons de gestion d’etat
La gestion d’etat est l’endroit ou la plupart des architectures d’agents s’effondrent discretement. Un agent de demo garde tout dans la fenetre de contexte du LLM et considere que c’est suffisant. Un agent en production doit gerer :
- Les taches de longue duree qui survivent a un cycle requete/reponse unique
- La reprise apres erreur sans re-executer les etapes completees
- L’acces concurrent quand plusieurs agents ou utilisateurs touchent des ressources partagees
- Les pistes d’audit qui reconstituent exactement ce qui s’est passe et pourquoi
Le patron le plus simple qui fonctionne en production est une machine a etats explicite. Chaque execution d’agent a un objet d’etat stocke dans un magasin durable (Postgres, Redis, DynamoDB). L’objet d’etat suit :
class AgentExecutionState:
execution_id: str
status: Literal["running", "waiting_human", "paused", "completed", "failed"]
current_step: int
steps_completed: list[CompletedStep]
context_snapshot: dict # contexte serialise au dernier checkpoint
tool_results: dict[str, Any] # resultats en cache par step_id
retry_count: int
created_at: datetime
last_checkpoint: datetimeChaque appel d’outil ecrit son resultat dans tool_results avant de continuer. Si l’execution plante a l’etape 8, le processus de recuperation charge l’etat, saute les etapes 1 a 7 (resultats deja en cache) et reprend a l’etape 8. Pas de re-execution. Pas d’effets de bord dupliques.
C’est basique, mais la plupart des equipes sautent cette etape au debut parce que la fenetre de contexte semble suffisante. Elle l’est, jusqu’a ce qu’une execution echoue au milieu d’un workflow de 14 etapes qui a deja envoye trois courriels et mis a jour deux enregistrements de base de donnees. Sans etat avec points de controle, vos options sont : tout re-executer (en dupliquant ces courriels) ou reconstituer manuellement ce qui s’est passe. Aucune des deux n’est acceptable.
Pour les systemes d’agents d’entreprise, la gestion d’etat signifie aussi l’isolation multi-locataire. L’Agent A qui travaille sur les donnees de l’Entreprise X ne doit jamais laisser fuiter son etat dans l’execution de l’Agent B pour l’Entreprise Y. Ca semble evident. En pratique, les magasins de contexte partages et les pools de connexions rendent l’erreur etonnamment facile.
Conception des outils : la decision architecturale negligee
La plupart des tutoriels de frameworks d’agents se concentrent sur comment appeler les outils. La question plus difficile est comment les concevoir. Une interface d’outil bien concue rend les agents plus fiables. Une mal concue les pousse a halluciner des parametres et a mal interpreter les resultats.
Les bonnes interfaces d’outils partagent quelques proprietes :
Des operations atomiques. Chaque outil fait une seule chose. get_customer_by_id est un bon outil. get_customer_and_update_subscription_and_send_email est trois outils qui pretendent n’en etre qu’un. Quand un outil compose echoue, impossible de savoir quelle operation a reussi. Quand on doit reessayer, impossible de sauter les parties deja completees.
Des entrees typees et contraintes. Au lieu d’accepter des chaines libres, les outils definissent des enums et des plages bornees. Un champ priority qui accepte "low" | "medium" | "high" vaut mieux qu’un qui accepte n’importe quelle chaine. Le LLM hallucine moins quand l’ensemble de valeurs valides est petit et explicite.
Des reponses d’erreur informatives. Quand un outil echoue, le message d’erreur doit dire a l’agent ce qui a mal tourne et quoi faire. "Customer not found" est inutile. "No customer with ID 12345. Did you mean to search by email? Use get_customer_by_email instead." donne a l’agent une voie de recuperation.
# Definition faible — vague, non typee, sans guide d'erreur
def search_records(query: str) -> str:
"""Search for records matching the query."""
...
# Definition forte — specifique, typee, erreurs actionnables
def get_customer_by_id(
customer_id: str, # Format UUID, ex. "550e8400-e29b..."
) -> CustomerRecord | ToolError:
"""
Recupere un enregistrement client unique par son ID.
Retourne CustomerRecord en cas de succes.
Retourne ToolError avec suggested_action si le client
n'est pas trouve ou si le format d'ID est invalide.
"""
...La description de l’outil fait partie du prompt. Chaque mot dans cette docstring coute des tokens et influence le comportement de l’agent. Ecrivez les descriptions d’outils comme vous ecririez de la documentation d’API pour un developpeur junior : precise, avec des exemples, couvrant les cas d’erreur.
Systemes de memoire : quoi retenir, quoi oublier
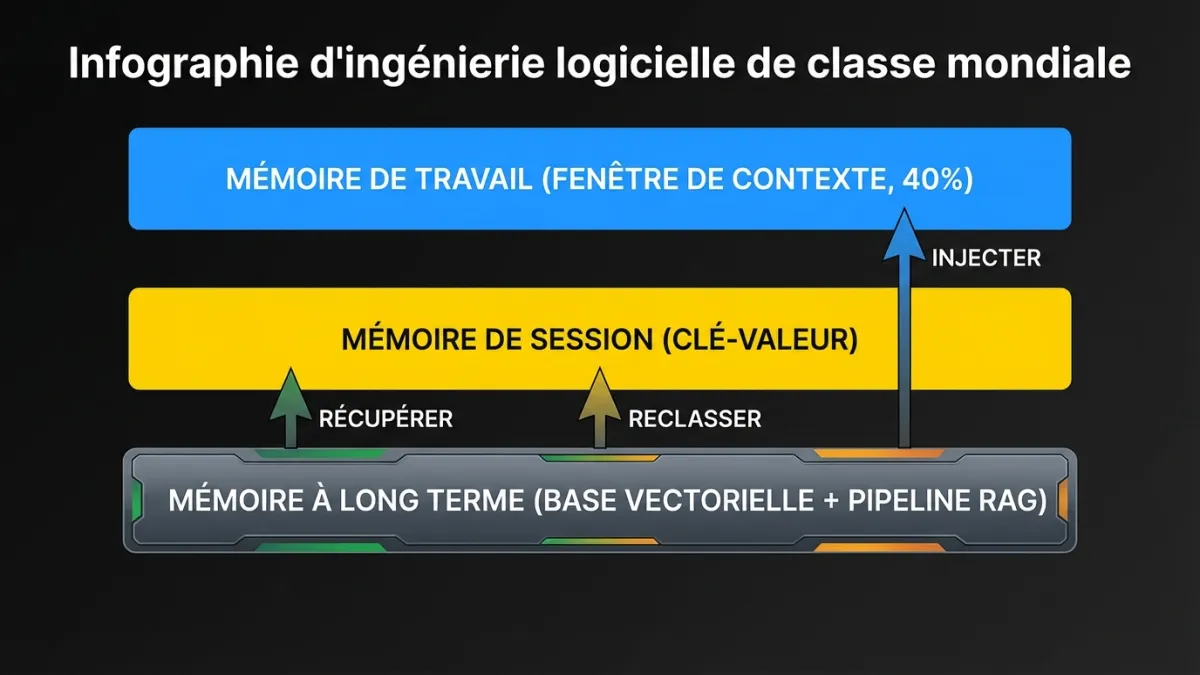
La memoire dans les agents en production fonctionne sur trois couches, chacune avec des strategies de stockage, de recuperation et d’eviction differentes.
La memoire de travail est le contexte d’execution actuel. La conversation jusqu’ici, les outils appeles, les resultats recus. Elle vit dans la fenetre de contexte du LLM et l’objet d’etat d’execution. Le defi est de faire tenir tout ce dont l’agent a besoin dans la fenetre de contexte sans depasser les limites de tokens.
La gestion de la fenetre de contexte est un probleme de remplissage actif. Une approche naive bourre tout jusqu’a ce que la fenetre soit pleine, puis tronque par le debut. Une meilleure approche note chaque element de contexte par pertinence pour la tache en cours et evince les elements peu pertinents en premier. Les resultats d’outils des premieres etapes qui ne sont pas references plus tard peuvent etre resumes ou supprimes. Les prompts systeme peuvent etre condenses pour les tours de continuation. On reserve typiquement 40 % de la fenetre de contexte pour le raisonnement et la sortie de l’agent, laissant 60 % pour le contexte d’entree. Ce ratio change selon que la tache est plus orientee recuperation ou generation.
La memoire de session persiste entre les tours au sein d’une meme session utilisateur. L’utilisateur a dit qu’il prefere les exports CSV au tour 2. Au tour 15, l’agent devrait s’en souvenir sans redemander. La memoire de session est generalement stockee dans un magasin cle-valeur rapide et injectee dans la fenetre de contexte au debut de chaque tour.
La memoire a long terme couvre plusieurs sessions. C’est la que les patrons de generation augmentee par recuperation (RAG) entrent en jeu. L’agent interroge un magasin vectoriel ou un index de recherche pour recuperer du contexte historique pertinent : conversations precedentes avec ce client, documentation sur ce produit, patrons appris de requetes similaires.
Le pipeline de recuperation compte plus que le modele d’embeddings. Un systeme de recuperation en production a besoin de scoring de pertinence, de ponderation par recence, de deduplication et de plafonnement de resultats. Deverser 20 fragments recuperes dans le contexte parce qu’ils ont tous un score au-dessus de 0,7 est un moyen rapide de crever votre budget de tokens et de desorienter l’agent. Recuperez plus que necessaire, reclassez agressivement, n’injectez que ce que l’agent utilisera reellement.
Savoir quand oublier est aussi important que savoir quoi retenir. Si chaque interaction est stockee de facon permanente, la memoire devient du bruit. L’information perimee degrade la qualite de recuperation au fil du temps. Les systemes en production ont besoin de politiques d’expiration. La memoire operationnelle (ce que l’utilisateur a demande aujourd’hui) expire en heures. La memoire de preference (l’utilisateur aime le CSV) expire en semaines ou mois. La memoire factuelle (le numero de compte de ce client) reste a jour par synchronisation ou est re-verifiee a l’acces.
Modes de defaillance et recuperation
Les defaillances d’agents different des defaillances logicielles traditionnelles. Un serveur web retourne un 500, et vous retentez la requete. Un agent echoue a l’etape 9 d’un workflow de 14 etapes, et vous devez determiner quelles etapes ont eu des effets de bord, lesquelles peuvent etre retentees en securite et lesquelles necessitent une revision humaine.
Le reessai est le patron le plus simple. L’appel d’outil a expire ? Rappeler. Le LLM a retourne du JSON mal forme ? Re-prompter avec un indice de correction. Les reessais fonctionnent pour les erreurs transitoires. Ils ne fonctionnent pas pour les erreurs logiques (l’agent a choisi le mauvais outil) ni pour les contraintes de ressources (la limite de debit de l’API sera toujours atteinte au reessai).
Le repli signifie basculer vers un chemin alternatif. Le LLM principal retourne des 503 ? Router vers le modele secondaire. L’API d’inventaire en temps reel est en panne ? Revenir au snapshot en cache d’il y a 15 minutes. Les replis exigent de definir des chemins alternatifs a la conception, pas d’esperer improviser en execution.
L’escalade transmet le probleme a un humain. L’agent n’a pas pu resoudre le probleme du client apres trois tentatives. Au lieu d’un quatrieme essai, il emballe le contexte d’execution complet (ce qu’il a essaye, ce qui a echoue, ce qu’il sait du client) et le route vers un operateur humain. Une bonne escalade inclut assez de contexte pour que l’humain ne reparte pas de zero.
Le coupe-circuit previent les defaillances en cascade. Si l’API de paiement a echoue 5 fois dans la derniere minute, arretez de l’appeler. Marquez le circuit comme ouvert. Retournez une erreur gracieuse a l’utilisateur. Reverifiez dans 30 secondes. Sans coupe-circuits, une dependance defaillante fait tomber chaque execution d’agent qui la touche.
class ToolCircuitBreaker:
def __init__(self, failure_threshold=5, reset_timeout_seconds=30):
self.failures = 0
self.threshold = failure_threshold
self.reset_timeout = reset_timeout_seconds
self.last_failure: datetime | None = None
self.state: Literal["closed", "open", "half_open"] = "closed"
def call(self, tool_fn, *args, **kwargs):
if self.state == "open":
if self._should_attempt_reset():
self.state = "half_open"
else:
raise CircuitOpenError(f"Circuit ouvert. Reessayer apres {self.reset_timeout}s.")
try:
result = tool_fn(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raiseLes systemes en production combinent les quatre patrons. Un appel d’outil reessaie deux fois, puis se replie sur un resultat en cache, puis escalade si les donnees en cache sont trop perimees. Les coupe-circuits protegent le service sous-jacent tout au long du processus.
Observabilite : pourquoi l’APM standard ne suffit pas
On peut surveiller une API REST avec des compteurs de requetes, des percentiles de latence et des taux d’erreur. Cette approche s’effondre pour les agents parce que les agents prennent des decisions. Deux entrees identiques peuvent produire des chemins d’execution completement differents selon le raisonnement du LLM. Suivre la latence et les taux d’erreur vous dit que quelque chose a echoue. Ca ne vous dit pas pourquoi l’agent a appele l’API de facturation au lieu de l’API de remboursement.
L’observabilite des agents exige le tracage de decisions. Chaque etape de l’execution a besoin d’une entree de trace qui capture :
- Le contexte que l’agent voyait au moment de la decision (pas juste l’appel d’outil, mais la fenetre de contexte tronquee qui a informe la decision)
- Les actions disponibles et pourquoi celle-ci a ete selectionnee
- Les parametres d’appel d’outil, la reponse et la latence
- La consommation de tokens a chaque etape
- Le raisonnement interne de l’agent (sortie chain-of-thought, si capturee)
Les outils APM standard (Datadog, New Relic, Jaeger) gerent la couche infrastructure : latence, debit, taux d’erreur. Ils ne comprennent pas la semantique au niveau agent. Une trace qui montre « appel LLM : 2,3 s, appel outil : 0,4 s, appel LLM : 1,8 s » vous donne le timing. Elle ne vous dit pas que l’agent a mal interprete le resultat de l’outil dans le deuxieme appel LLM et a pris un mauvais chemin pendant six etapes de plus.
Des outils comme LangSmith, Arize Phoenix et Braintrust construisent une observabilite native pour les agents. Ils capturent le graphe de decisions complet, pas juste la cascade de timing. Si vous executez des agents en production sans ce niveau de tracage, vous deboguez a l’aveugle.
La configuration d’observabilite minimale viable pour un agent en production :
- Journaux d’execution avec le contexte complet a chaque point de decision (stockes, pas juste diffuses)
- Suivi des couts par execution (modele, tokens entrants, tokens sortants, couts d’appels d’outils)
- Rejeu de decisions (avec le meme contexte, pouvez-vous reproduire les choix de l’agent ?)
- Detection d’anomalies sur les patrons d’execution (l’agent prend soudainement 3x plus d’etapes que d’habitude ? Alertez.)
- Suivi des resultats utilisateur (l’agent a-t-il vraiment resolu le probleme de l’utilisateur, pas juste complete l’execution ?)
Patrons architecturaux
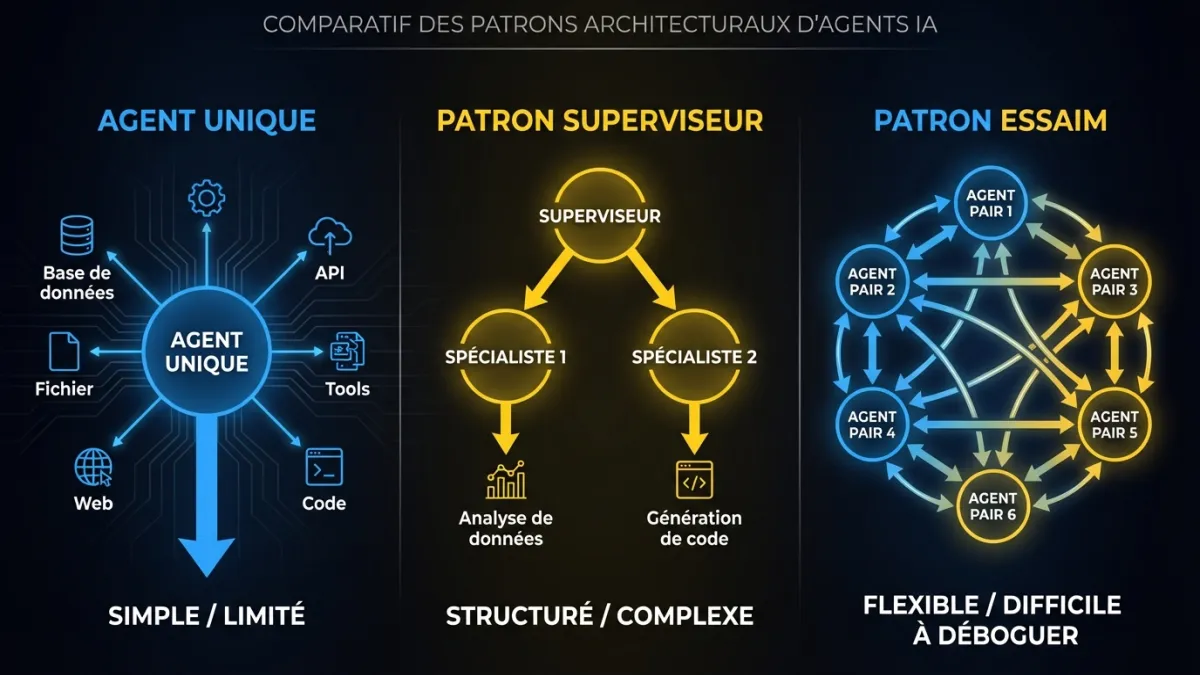
Trois patrons couvrent la plupart des deploiements d’agents en production. Le choix depend de la complexite de la tache et du nombre de capacites distinctes dont le systeme a besoin.
Agent unique avec routage d’outils
Un agent, un LLM, plusieurs outils. L’agent decide quel outil appeler a chaque etape. C’est le bon patron quand le domaine de la tache est borne et qu’un seul modele peut gerer tout le raisonnement.
La plupart des agents de support client, des agents de recuperation de donnees et des agents de workflows internes entrent dans cette categorie. L’agent a 10 a 30 outils, route entre eux selon la requete de l’utilisateur et gere l’interaction complete. La complexite reste gerable parce qu’un seul agent possede toute l’execution.
La limite est la pression sur la fenetre de contexte. A mesure qu’on ajoute des outils, chaque schema consomme des tokens. Au-dela de 40 outils, l’agent commence a perdre en precision sur la selection d’outil parce que le contexte est encombre. L’ingenierie de prompt aide (grouper les outils relies, fournir des indices de selection), mais il y a un plafond pratique.
Orchestration multi-agent : patron superviseur
Un agent superviseur recoit la requete, la decompose en sous-taches et delegue chacune a un agent specialiste. Le superviseur coordonne les resultats et gere les dependances entre agents.
Ca fonctionne bien quand le systeme a besoin d’une expertise approfondie dans plusieurs domaines. Un workflow d’IA agentique qui traite des reclamations d’assurance pourrait utiliser un agent d’extraction de documents, un agent de recherche de polices, un agent de detection de fraude et un agent de communication. Chaque specialiste a un ensemble d’outils focalise et des prompts optimises. Le superviseur gere le sequencement et la resolution de conflits.
La partie delicate est le protocole de communication entre agents. Les agents peuvent partager l’etat via un magasin commun (le patron tableau noir) ou par passage de messages structures. Le patron tableau noir est plus simple mais plus difficile a deboguer : n’importe quel agent peut modifier l’etat partage a tout moment, et retracer quel agent a ecrit quoi exige un journalisation minutieuse. Le passage de messages est plus explicite mais ajoute du surcout en serialisation et deserialisation de contexte entre agents.
Orchestration multi-agent : patron essaim
Pas de superviseur central. Les agents se coordonnent par etat partage et protocoles de transfert. Chaque agent sait quand passer le controle a un autre agent selon la tache en cours.
Le framework Swarm d’OpenAI a popularise ce patron. Il fonctionne en donnant a chaque agent une fonction handoff qui transfere l’execution (et le contexte) a un autre agent. La conversation coule entre les agents organiquement selon les besoins de l’utilisateur.
Le patron essaim excelle dans les interfaces conversationnelles ou le « bon » agent depend du besoin actuel de l’utilisateur, pas d’une decomposition de tache predeterminee. Un client appelle pour une question de facturation, est route vers l’agent de facturation, mentionne un probleme technique, est transfere a l’agent de support, demande une mise a niveau, est transfere a l’agent commercial. Pas besoin de superviseur.
L’inconvenient est la coordination. Sans superviseur, aucun point unique ne comprend l’etat d’execution complet. Si quelque chose tourne mal, il faut reconstituer le chemin d’execution a partir des journaux individuels de chaque agent. Ce patron necessite l’investissement en observabilite le plus fort.
Integration humain-dans-la-boucle
Les points de controle d’approbation humaine ne se greffent proprement sur aucun de ces patrons. Ils exigent une conception explicite parce qu’ils brisent le flux d’execution de l’agent.
L’implementation pratique : quand l’agent atteint une decision qui requiert une approbation humaine (envoyer un courriel a un client, executer une transaction au-dessus d’un seuil, modifier une configuration de production), il ecrit son etat actuel dans le magasin de points de controle, emet une demande d’approbation dans une file d’attente et s’arrete. L’execution entre dans un etat waiting_human. Un humain examine l’action proposee, approuve ou rejette. Sur approbation, l’execution reprend du point de controle. Sur rejet, l’agent recoit la raison du rejet et replanifie.
La partie difficile est la gestion du delai d’expiration. Et si l’humain ne repond pas pendant 6 heures ? Le contexte peut etre perime a ce moment-la. Les donnees client peuvent avoir change. L’agent doit savoir s’il reprend avec le contexte original ou re-collecte des donnees fraiches. Il n’y a pas de reponse universelle. Ca depend du domaine. Les transactions financieres devraient re-verifier. Les approbations de contenu peuvent generalement reprendre telles quelles.
Ce que les frameworks font mal
Les frameworks d’agents IA accelerent le prototypage. Ils creent aussi des cauchemars de debogage a grande echelle. La friction vient de trois patrons.
La sur-abstraction cache le prompt. Quand le framework construit le prompt a partir de votre configuration, vous perdez la visibilite sur ce que le LLM voit reellement. Une definition d’outil que vous pensiez claire est reformatee en quelque chose d’ambigu. L’agent se comporte mal, et vous ne pouvez pas dire si le probleme vient de votre prompt, de la construction du prompt par le framework ou de l’interpretation du modele. La premiere etape de debogage est toujours « imprimer le prompt reel ». Si votre framework rend ca difficile, il vous coute du temps.
La gestion d’etat magique cree un couplage invisible. Certains frameworks gerent la memoire de l’agent et l’etat de conversation via des magasins internes qui se mettent a jour implicitement. Votre agent se comporte differemment au cinquieme tour qu’au premier, et vous n’etes pas sur de ce qui a change parce que les mutations d’etat se produisent dans les internes du framework. La gestion d’etat explicite (vous possedez l’objet d’etat, vous decidez ce qui entre et ce qui sort) c’est plus de code et plus de clarte.
Les couches d’abstraction combattent votre infrastructure. Le framework veut gerer ses propres clients HTTP, pools de connexions, logique de reessai et journalisation. Votre infrastructure a deja des opinions sur tout ca. Faire tourner les deux cree des conflits : journaux dupliques, politiques de reessai concurrentes, epuisement des pools de connexions. Les fonctionnalites de commodite du framework deviennent des responsabilites operationnelles.
Rien de tout ca ne signifie que les frameworks sont mauvais. Pour les prototypes et les outils internes, utilisez-les. Pour les systemes de production qui doivent fonctionner de facon fiable a grande echelle, evaluez si le framework vous fait gagner du temps ou cree une taxe de debogage. Beaucoup d’equipes commencent avec un framework et remplacent graduellement ses internes par des implementations personnalisees quand les problemes de mise a l’echelle apparaissent. C’est un chemin raisonnable, tant que l’architecture du framework permet le remplacement progressif.
Notre equipe construit des systemes d’agents sur mesure quand les exigences de production depassent ce que les frameworks offrent. Le point de decision est generalement clair : si vous passez plus de temps a contourner le framework qu’a travailler avec, l’abstraction est devenue une responsabilite.
Evaluation : tester les agents avant et apres le deploiement
L’evaluation d’agents est plus difficile que le test de logiciel traditionnel parce que les sorties sont non deterministes. La meme entree peut produire des sorties differentes (mais egalement valides) d’une execution a l’autre. Les tests unitaires passe/echoue ne capturent pas le portrait complet.
L’evaluation pre-deploiement utilise des suites de tests curees qui couvrent les chemins critiques. Chaque cas de test definit une entree, les actions attendues (quels outils devraient etre appeles, dans quel ordre) et les criteres de succes (la sortie devrait contenir X, la base de donnees devrait refleter Y). Executez la suite a chaque changement de prompt, mise a jour de modele ou modification d’outil. Suivez les taux de reussite dans le temps. Une chute de 94 % a 87 % apres une modification de prompt signifie que la modification a casse quelque chose.
L’evaluation post-deploiement surveille les executions en direct pour les regressions de qualite. Echantillonnez un pourcentage d’executions, passez-les dans des verifications de qualite automatisees (l’agent a-t-il resolu la requete de l’utilisateur ? a-t-il appele les outils dans une sequence raisonnable ?), et signalez les valeurs aberrantes pour revision humaine. Ca capture la derive que le test pre-deploiement manque : changements de comportement utilisateur, modifications de format de reponse d’API, mises a jour de comportement de modele.
Les tests adversariaux sondent les limites de l’agent. Donnez-lui des entrees ambigues. Donnez-lui des instructions contradictoires. Presentez des resultats d’outils techniquement valides mais trompeurs. Les agents en production rencontrent tout ca. Les tests devraient aussi.
Le harnais d’evaluation est aussi important que l’agent lui-meme. Les equipes qui traitent l’evaluation comme une reflexion apres coup passent leur temps a eteindre des feux en production. Les equipes qui investissent dans l’infrastructure d’evaluation attrapent les problemes avant les utilisateurs.
La version honnete
Construire des agents IA pour la production est un probleme d’ingenierie systeme, pas un probleme d’ingenierie de prompts. Le LLM est le moteur de raisonnement. Tout ce qui l’entoure (gestion d’etat, gestion des erreurs, observabilite, conception d’outils, evaluation) est ce qui le rend pret pour la production.
Si vous demarrez un projet d’agent, passez votre premiere semaine sur l’infrastructure, pas les prompts. Mettez en place les points de controle d’etat. Construisez des coupe-circuits pour vos appels d’outils. Instrumentez le tracage de decisions des le premier jour. Faites tourner l’evaluation avant de presenter l’agent a qui que ce soit.
La demo fonctionnera sans tout ca. La production, non.
Vous etes pret a construire des agents IA de calibre production ? Notre equipe a livre des systemes d’agents dans plusieurs industries. Contactez-nous pour discuter de votre architecture.