Entre « on a besoin d’une stratégie IA » et « on a livré une fonctionnalité IA », la plupart des équipes produit perdent le fil. Le problème n’est pas l’ambition. C’est l’implémentation.
On s’est intégrés dans des dizaines d’équipes produit au cours des deux dernières années. Certaines avaient une feuille de route IA claire. D’autres n’avaient qu’un mandat du CA et un vague sentiment d’urgence. Le patron qu’on observe sans cesse : les équipes qui réussissent traitent l’implémentation de l’IA comme une discipline d’ingénierie. Celles qui échouent la traitent comme un projet avec une date de livraison et une démo.
Ce guide couvre le cadre d’implémentation qu’on utilise quand on s’intègre dans les équipes produit. Même approche, que l’objectif soit d’ajouter de l’intelligence à un produit existant ou de construire une nouvelle fonctionnalité native IA.
Pourquoi la plupart des implémentations IA échouent
Avant le cadre, les modes d’échec. Ce ne sont pas des hypothèses. Ils viennent d’engagements réels où on a été appelés après que la première tentative ait calé.
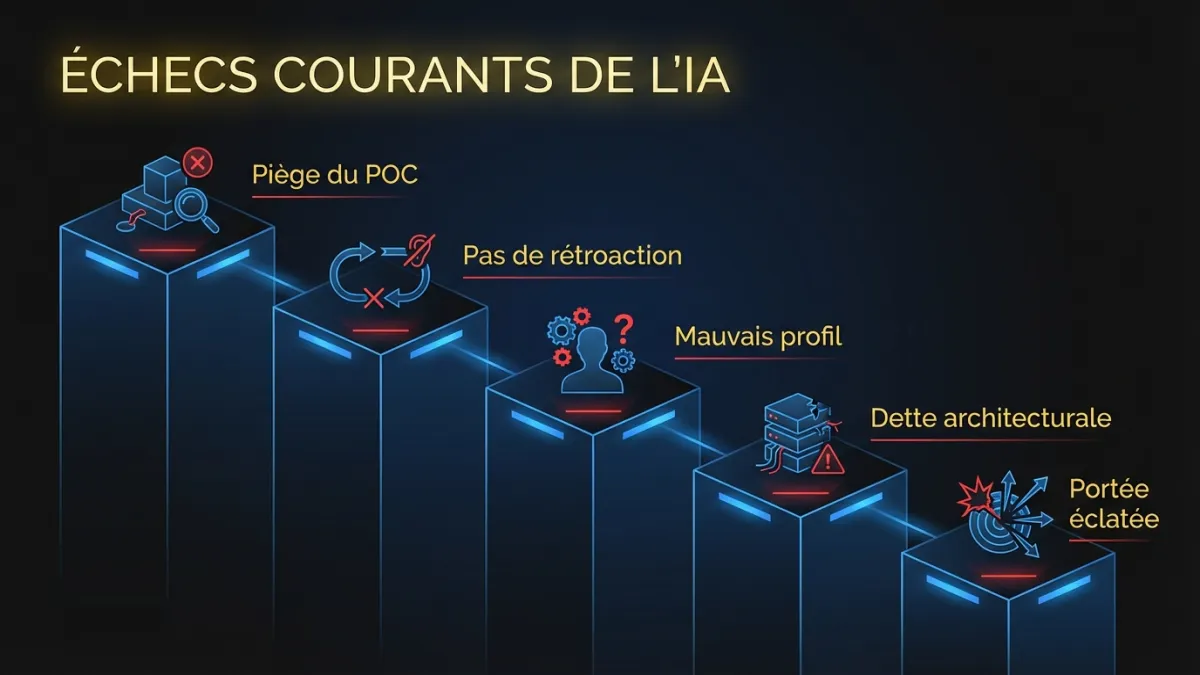
Mode d’échec 1 : Le piège de la preuve de concept
Une petite équipe construit un POC en deux semaines. La démo impressionne. La direction donne le feu vert pour la production. Six mois plus tard, l’équipe se bat encore avec des cas limites, des problèmes de latence et des enjeux de qualité de données qui n’existaient pas dans l’environnement contrôlé de la démo.
L’écart entre POC et production en IA est plus grand qu’en logiciel traditionnel. Un modèle de classification qui fonctionne sur 500 exemples soigneusement sélectionnés se comporte différemment sur 500 000 entrées réelles et désordonnées. Un modèle de langage qui produit des résultats propres dans un notebook Jupyter hallucine quand les utilisateurs lui soumettent des requêtes inattendues. Les POC prouvent que l’IA peut faire quelque chose. Ils ne disent rien sur sa capacité à le faire de façon fiable, à grande échelle, pour de vrais utilisateurs.
Mode d’échec 2 : Pas d’architecture de rétroaction
L’équipe livre une fonctionnalité IA. Ça fonctionne. Plus ou moins. Mais il n’y a aucun mécanisme pour mesurer ce « plus ou moins ». Aucun moyen de capturer quand la sortie du modèle était erronée. Aucun pipeline pour transformer les corrections des utilisateurs en signal d’entraînement. Aucune alerte quand les scores de confiance tombent sous les seuils acceptables.
Six mois plus tard, la précision s’est dégradée parce que la distribution des données sous-jacentes a changé. Personne ne l’a remarqué jusqu’à ce que les plaintes clients explosent. L’équipe se démène, mais elle n’a aucun jeu de données étiqueté des échecs parce qu’elle n’a jamais construit l’instrumentation.
Mode d’échec 3 : Embaucher le mauvais profil
Le VP ingénierie publie une offre pour un « Ingénieur senior en apprentissage automatique ». Le poste demande de l’expertise PyTorch, des publications et de l’expérience avec les architectures transformer. L’équipe embauche quelqu’un de brillant. Cette personne passe ses trois premiers mois à demander des données d’entraînement étiquetées qui n’existent pas, un cluster GPU que l’entreprise ne peut pas se payer, et un pipeline de données qui prendrait une équipe de trois personnes six mois supplémentaires à construire.
Le vrai besoin était un ingénieur logiciel senior avec de l’expérience dans l’intégration d’API de modèles fondamentaux, la construction de cadres d’évaluation et la conception de dégradation gracieuse quand le composant IA échoue. Un profil de compétences complètement différent.
Mode d’échec 4 : L’architecture comme réflexion tardive
L’équipe choisit un modèle, construit une fonctionnalité et la déploie dans le monolithe existant. L’appel d’inférence IA ajoute 2,3 secondes à un flux de travail qui prenait auparavant 400 millisecondes. Les utilisateurs détestent ça. L’équipe tente d’optimiser, mais le modèle est couplé au cycle requête-réponse sans chemin asynchrone. Réarchitecturer signifie réécrire la moitié de la fonctionnalité.
Les fonctionnalités IA ont des caractéristiques de performance différentes du logiciel traditionnel. Elles nécessitent un traitement architectural différent. Boulonner l’IA sur une architecture existante sans planifier la latence, les replis et le traitement asynchrone crée une dette technique coûteuse à démêler.
Mode d’échec 5 : La portée sans séquence
La direction approuve six fonctionnalités IA dans trois domaines produit. L’équipe essaie de les construire toutes en parallèle. Chaque fonctionnalité nécessite son propre pipeline de données, cadre d’évaluation et travail d’intégration. La bande passante d’ingénierie se fragmente. Rien ne sort pendant huit mois. Le CA perd confiance. L’initiative IA est discrètement rétrogradée.
Une fonctionnalité, bien livrée, avec de l’instrumentation et des boucles de rétroaction, enseigne plus à l’équipe que six fonctionnalités définies dans PowerPoint.
Le cadre d’implémentation
Cinq phases. Séquentielles, mais avec du travail en parallèle à l’intérieur de chaque phase. Délai total de la phase un à une fonctionnalité en production : 8 à 16 semaines, selon la disponibilité des données et la complexité du produit.

Phase 1 : Évaluation (semaines 1-2)
Avant d’écrire du code, répondez à quatre questions.
Quel problème utilisateur l’IA résout-elle? Pas « où peut-on utiliser l’IA? » mais « où les utilisateurs passent-ils du temps sur des tâches que les machines gèrent mieux? » Si vous avez déjà fait le travail dans une stratégie produit IA, cette étape est simple. Sinon, commencez par là.
Quelles données existent aujourd’hui? Inventoriez vos actifs de données avec précision. « On a des données clients » n’est pas une réponse. « On a 14 mois de textes de tickets de support, catégorisés par type de problème, avec des horodatages de résolution et des scores de satisfaction client » est une réponse. La qualité et la structure de vos données existantes déterminent ce qui est faisable maintenant versus ce qui nécessite d’abord une phase de collecte de données.
Quel est le taux d’erreur acceptable? Les fonctionnalités IA sont probabilistes. Elles se tromperont parfois. Définir « à quel point c’est trop erroné » avant de construire quoi que ce soit force des conversations honnêtes sur les attentes des utilisateurs. Une recommandation de produit non pertinente 20 % du temps, c’est acceptable. Une suggestion de dosage médical erronée 1 % du temps, ce ne l’est pas.
Que se passe-t-il quand l’IA se trompe? Chaque fonctionnalité IA a besoin d’un repli. Que voit l’utilisateur? Peut-il corriger la sortie? La correction est-elle capturée comme signal d’entraînement? L’expérience de repli est aussi importante que l’expérience principale.
Documentez les réponses. Partagez-les avec l’équipe. Ces quatre questions éliminent plus d’efforts gaspillés que n’importe quelle décision technique.
Phase 2 : Sélection du pilote (semaines 2-3)
Choisissez une fonctionnalité. Pas deux. Une.
Le pilote idéal a cinq caractéristiques :
- Haute fréquence. Les utilisateurs rencontrent ce flux de travail quotidiennement ou plusieurs fois par semaine. La haute fréquence signifie des boucles de rétroaction plus rapides et un impact plus mesurable.
- Tolérance à l’imperfection. La fonctionnalité est additive, pas un remplacement. L’utilisateur peut ignorer ou remplacer la sortie IA sans casser son flux de travail. Les auto-suggestions, la génération de brouillons et les valeurs par défaut intelligentes correspondent à ce patron.
- Données existantes. Vous pouvez construire une première version sans nouvel effort de collecte de données. Les API de modèles fondamentaux avec un bon prompt engineering couvrent beaucoup de cas d’usage sans données d’entraînement personnalisées.
- Métrique de succès claire. Vous pouvez mesurer si la fonctionnalité marche avec les analytiques existantes. Temps gagné par tâche, taux d’adoption, taux de remplacement ou taux de complétion des tâches.
- Rayon d’impact contenu. Si la fonctionnalité échoue ou se dégrade, l’impact est limité. Une mauvaise suggestion dans un champ texte est agaçante. Un mauvais calcul dans un flux de facturation est une crise.
L’équipe voudra choisir la fonctionnalité la plus impressionnante. Résistez. Choisissez celle que vous pouvez livrer en quatre semaines, mesurer en deux de plus, et dont vous pouvez tirer des apprentissages. L’apprentissage se compose dans chaque fonctionnalité suivante.
Phase 3 : Décisions d’architecture (semaines 3-5)
Trois patrons d’architecture couvrent 80 % des fonctionnalités IA dans les produits existants. Votre pilote utilisera l’un d’entre eux, et ce choix façonne tout en aval.
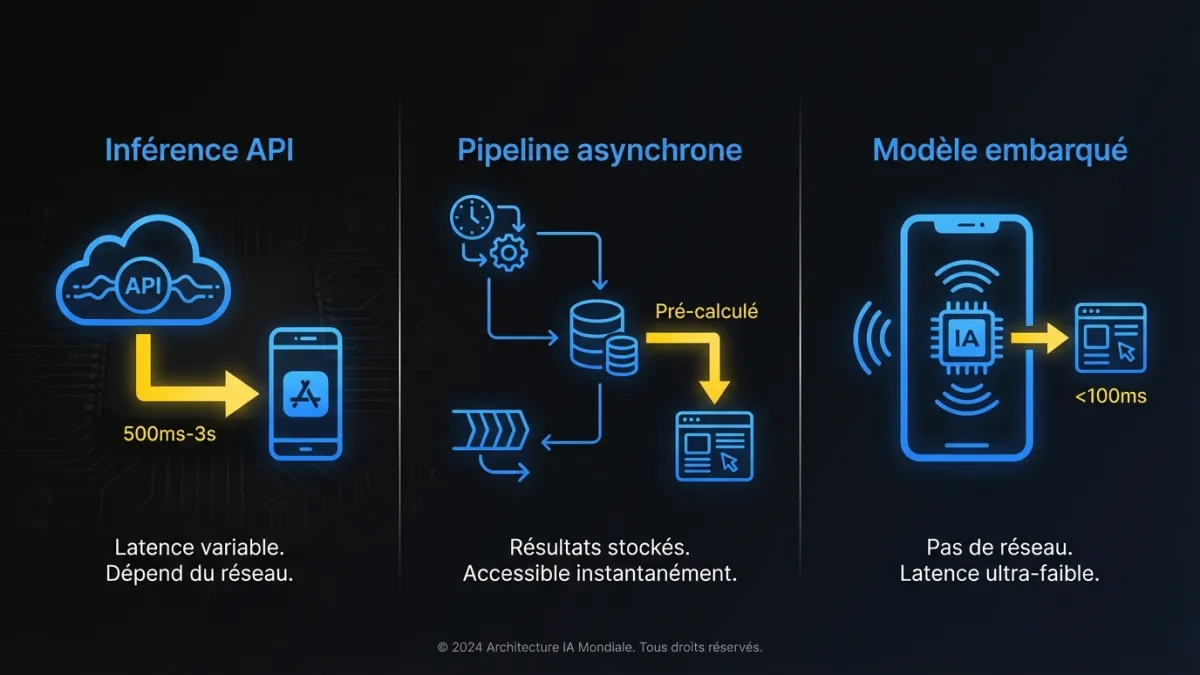
Patron 1 : Inférence via API. Votre produit appelle une API de modèle fondamental (OpenAI, Anthropic, Google, ou un modèle auto-hébergé derrière une passerelle API) au moment où l’apport IA est nécessaire. Le modèle traite la requête et retourne un résultat que votre application formate et affiche.
Idéal pour : génération de texte, résumé, classification, extraction, fonctionnalités conversationnelles. Toute tâche où un modèle fondamental performe bien avec du prompt engineering et le contexte de votre produit.
Attention à : la latence (les allers-retours API ajoutent 500ms-3s selon la longueur de la sortie), le coût à l’échelle (la tarification par jeton s’accumule avec les fonctionnalités à haute fréquence), et la dépendance au fournisseur.
Patron 2 : Pipeline asynchrone avec pré-calcul. Au lieu d’appeler un modèle dans le chemin de la requête, vous exécutez l’inférence comme tâche en arrière-plan. Les résultats sont pré-calculés et stockés, puis servis instantanément quand l’utilisateur en a besoin.
Idéal pour : recommandations, correspondance de similarité, catégorisation de contenu, détection d’anomalies. Toute fonctionnalité où les données d’entrée ne changent pas au moment où l’utilisateur demande la sortie.
Attention à : l’obsolescence (les résultats pré-calculés peuvent être périmés quand l’utilisateur les voit), les coûts de stockage et la complexité du pipeline.
Patron 3 : Modèle embarqué avec inférence en périphérie. Un modèle plus petit et affiné tourne dans votre infrastructure applicative. Aucun appel API externe. Le modèle est déployé comme microservice ou processus sidecar.
Idéal pour : fonctionnalités nécessitant une latence sous 100ms, cas d’usage sensibles à la vie privée où les données ne peuvent pas quitter votre infrastructure, ou tâches spécialisées où un petit modèle affiné surpasse un grand modèle généraliste.
Attention à : la charge opérationnelle (vous gérez maintenant de l’infrastructure ML), le besoin de pipelines d’affinage, et les compétences requises pour maintenir des modèles déployés.
La plupart des équipes devraient commencer avec le Patron 1. Charge opérationnelle minimale. Vous pouvez livrer en semaines plutôt qu’en mois. Et vous apprenez ce qui compte avant d’investir dans l’infrastructure. Passez au Patron 2 ou 3 quand les données d’utilisation indiquent que la latence, le coût ou la sensibilité des données l’exigent.
Pour les produits explorant des architectures IA agentiques, un quatrième patron émerge : des agents multi-étapes orchestrés qui enchaînent les appels de modèles avec l’utilisation d’outils. C’est une implémentation plus avancée qui mérite son propre traitement, mais les mêmes principes de séquençage s’appliquent. Commencez simple. Ajoutez de la complexité quand l’approche plus simple échoue de façon démontrable.
Quel que soit le patron, intégrez trois éléments dans l’architecture dès le premier jour :
Un chemin de repli. Quand le composant IA échoue (et ça arrivera), l’expérience utilisateur se dégrade gracieusement. Montrez la version sans IA. Affichez un état « en génération ». Ne montrez jamais un indicateur de chargement qui tourne pendant 30 secondes.
Un harnais d’évaluation. Des tests automatisés qui exécutent un ensemble fixe d’entrées dans votre pipeline IA et comparent les sorties aux résultats attendus. C’est votre suite de régression. Chaque fois que vous changez un prompt, échangez un modèle ou mettez à jour un pipeline, le harnais vous dit si la qualité s’est améliorée ou a régressé.
Un mécanisme de capture de rétroaction. Pouce en haut/bas, corrections explicites, signaux implicites (l’utilisateur a-t-il accepté la suggestion ou l’a-t-il supprimée?). Ces données deviennent votre atout d’entraînement le plus précieux au fil du temps.
Phase 4 : Structure de l’équipe (en parallèle avec la Phase 3)
Vous avez besoin de trois capacités dans l’équipe d’implémentation. La question est comment les pourvoir.
Ingénierie IA. Les personnes qui conçoivent les prompts, construisent les cadres d’évaluation, sélectionnent les modèles et optimisent l’inférence. Ce n’est pas de la recherche ML traditionnelle. C’est de l’ingénierie IA appliquée : faire fonctionner les modèles de façon fiable dans un contexte produit.
Ingénierie produit. Les personnes qui intègrent le composant IA dans votre produit existant. Elles sont responsables de l’interface, des contrats d’API, du flux de données et des chemins de repli. Idéalement, les ingénieurs qui possèdent déjà le domaine fonctionnel où l’IA est ajoutée.
Ingénierie des données. Les personnes qui construisent et maintiennent les pipelines de données alimentant le composant IA. Préparation des données d’entrée, extraction de caractéristiques, stockage des boucles de rétroaction et gestion des jeux de données d’évaluation.
Trois modèles de dotation, avec des compromis honnêtes :
Embaucher. Des ingénieurs IA à temps plein dans votre équipe. Meilleur investissement à long terme, mais les ingénieurs IA seniors prennent 4-6 mois à recruter dans le marché actuel. Si votre échéancier est de 8-16 semaines, l’embauche n’est pas votre stratégie de Phase 1. C’est votre stratégie de Phase 3 pour les fonctionnalités deux et trois.
Intégrer. Faire venir des ingénieurs IA externes qui travaillent dans votre équipe, utilisent vos outils, assistent à vos mêlées quotidiennes et livrent dans votre cycle de release. Plus rapide que l’embauche. Les ingénieurs intégrés transfèrent les connaissances à votre équipe en construisant. Quand ils partent, votre équipe est plus forte qu’avant. C’est ce qu’on fait, alors prenez la recommandation avec le contexte approprié. La raison pour laquelle on a construit notre entreprise autour de ce modèle est qu’on l’a vu fonctionner à répétition tandis que les alternatives échouaient.
Sous-traiter. Confier la fonctionnalité IA à une agence externe qui la construit séparément et la livre pour intégration. Plus rapide à démarrer, mais le transfert crée des problèmes. L’agence ne connaît pas votre base de code en profondeur. La surface d’intégration est là où les bogues vivent. Et quand la fonctionnalité a besoin d’itérations (ce sera le cas), vous êtes de retour dans l’échéancier et les priorités de l’agence.
La plupart des équipes avec lesquelles on travaille utilisent un modèle hybride : des ingénieurs IA intégrés pour les deux premières fonctionnalités, puis une transition vers un mélange d’intégrés et d’embauchés à mesure que l’équipe interne monte en compétences. Le pire résultat est de sous-traiter la première fonctionnalité, obtenir quelque chose qui fonctionne en isolation, puis peiner à le maintenir avec une équipe qui ne l’a pas construit.
Phase 5 : Déploiement et mesure (semaines 6-16)
Livrez d’abord à un petit groupe. 5-10 % des utilisateurs, ou une cohorte client spécifique qui a accepté de participer. L’objectif n’est pas un test bêta. C’est une validation en production avec des patrons d’utilisation réels à échelle contrôlée.
Semaines 6-8 : Déploiement limité. Livrez la fonctionnalité derrière un feature flag. Surveillez quatre métriques :
- Taux d’adoption. Quel pourcentage d’utilisateurs éligibles interagit avec la fonctionnalité? Sous 15 % après deux semaines signifie que la fonctionnalité est difficile à découvrir ou pas convaincante.
- Taux de remplacement. À quelle fréquence les utilisateurs rejettent-ils ou modifient-ils la sortie IA? Au-dessus de 40 % signifie que le modèle n’est pas assez bon. Sous 10 % et vous mesurez peut-être mal (les utilisateurs ne savent peut-être pas qu’ils peuvent remplacer).
- Latence. Temps de réponse P50 et P99 pour le composant IA. Si le P99 dépasse 4 secondes pour une fonctionnalité en ligne, vous avez besoin de traitement asynchrone ou d’un modèle plus rapide.
- Taux d’erreur. À quelle fréquence le composant IA échoue-t-il complètement? Cible sous 2 % pour la production.
Semaines 8-12 : Itérer et élargir. Utilisez les données du déploiement limité pour améliorer les prompts, ajuster les seuils, corriger les cas limites. Élargissez à 25 %, puis 50 % des utilisateurs. Chaque élargissement est un point de décision : les métriques tiennent-elles à plus grande échelle?
Semaines 12-16 : Disponibilité générale. Déploiement complet avec tableaux de bord de surveillance, alertes sur les régressions de métriques et un processus d’astreinte défini pour les incidents spécifiques à l’IA.
L’échéancier n’est pas arbitraire. Huit semaines du code au déploiement limité est agressif mais atteignable pour une implémentation Patron 1 avec de bonnes données. Les Patrons 2 et 3 ajoutent 4-6 semaines pour le travail d’infrastructure. Si quelqu’un promet une fonctionnalité IA en production en deux semaines, il décrit soit un POC, soit il a déjà fait cette exacte implémentation avec la même architecture.
Construire vs. acheter vs. intégrer : un cadre de décision
Cette question revient dans chaque implémentation IA. La réponse dépend de la place de l’IA dans votre chaîne de valeur.
Construisez quand l’IA est la valeur fondamentale de votre produit. Si la capacité IA est ce pour quoi vos clients paient, et que la qualité de cette IA est votre différenciation concurrentielle, construisez-la. Possédez les modèles, les données d’entraînement, le cadre d’évaluation. Un produit de recherche natif IA ne devrait pas dépendre entièrement d’une API tierce pour son algorithme de classement principal.
Achetez quand l’IA est de l’infrastructure. Si vous avez besoin d’une capacité IA qui n’est pas différenciante mais nécessaire, achetez-la. Filtrage de spam, modération de contenu, traduction, OCR. Ce sont des problèmes résolus avec de bonnes solutions commerciales. Construire votre propre filtre anti-spam n’est pas une utilisation stratégique du temps d’ingénierie.
Intégrez quand l’IA est une nouvelle capacité que votre équipe n’a pas. Si votre produit a besoin de fonctionnalités IA et que votre équipe n’a pas l’expérience pour les implémenter correctement, intégrer de l’expertise externe vous amène en production plus vite que l’embauche ou la sous-traitance. L’équipe intégrée construit les premières fonctionnalités pendant que vos ingénieurs existants apprennent à leurs côtés. Dès la deuxième ou troisième fonctionnalité, votre équipe peut mener le travail.
Les frontières se brouillent. Une fonctionnalité peut commencer comme « acheter » (utiliser une API de modèle fondamental) et évoluer vers « construire » (affiner votre propre modèle sur des données propriétaires) à mesure que l’utilisation croît et que la différenciation compte davantage. C’est normal. Le cadre d’implémentation est conçu pour cette évolution. Patron 1 aujourd’hui, Patron 3 dans six mois, avec des harnais d’évaluation assurant la qualité tout au long de la transition.
Si vous évaluez par où commencer, le guide pour ajouter l’IA aux produits existants couvre les décisions au niveau produit plus en profondeur.
À quoi ressemble le succès à chaque étape
Les équipes mesurent souvent le succès d’une implémentation IA avec un seul critère binaire : la fonctionnalité a-t-elle été livrée? Ça rate l’essentiel. Les fonctionnalités IA sont des systèmes vivants. Le succès a des étapes.
Après les Phases 1-2 (Évaluation + Sélection du pilote) : Vous avez une feuille de route IA documentée avec une fonctionnalité pilote clairement définie. L’équipe s’entend sur la métrique de succès et le taux d’erreur acceptable. Il n’y a pas encore de code, et c’est correct. Sauter cette phase est la source la plus courante d’effort d’ingénierie gaspillé.
Après la Phase 3 (Architecture) : Le composant IA tourne dans un environnement de staging. Le harnais d’évaluation passe avec une qualité de sortie au-dessus de votre seuil défini. Le chemin de repli fonctionne. La capture de rétroaction est instrumentée. Vous n’avez pas encore touché l’interface de production.
Après le déploiement limité (Semaine 8) : Vous avez des données d’utilisation réelles. Vous connaissez le taux d’adoption, le taux de remplacement et la distribution de latence. Vous avez identifié les cinq principaux cas limites et corrigé au moins trois. Vous pouvez répondre à « cette fonctionnalité vaut-elle la peine d’être élargie? » avec des données, pas des opinions.
Après la disponibilité générale (Semaine 16) : La fonctionnalité tourne en production pour tous les utilisateurs. La surveillance et les alertes sont actives. L’équipe a un guide de réponse pour la dégradation de modèle. Les données de rétroaction s’accumulent. Vous avez un backlog d’améliorations classées par impact. Et, surtout, vous avez une équipe qui sait comment refaire ça pour la prochaine fonctionnalité.
Après 6 mois : La boucle de rétroaction a produit une amélioration mesurable de la qualité. Vous avez livré une deuxième fonctionnalité IA en moitié moins de temps que la première. L’équipe débat des patrons d’architecture à partir d’expérience, pas de théorie. L’implémentation IA est une capacité d’ingénierie que l’organisation possède, pas un projet spécial qui nécessitait de l’aide extérieure.
Attentes de délais, ancrées dans la réalité
Les équipes de direction sous-estiment fréquemment les délais d’implémentation IA. Voici ce qu’on observe dans nos engagements réels.
Intégration d’API de modèle fondamental (Patron 1), fonctionnalité unique : 8-12 semaines du lancement à la disponibilité générale. Cela suppose que les données existent, l’équipe est pourvue et la fonctionnalité est bien définie. Premières quatre semaines : évaluation, architecture, staging. Quatre suivantes : déploiement et itération. Quatre dernières : élargissement et renforcement.
Pipeline asynchrone avec pré-calcul (Patron 2) : 12-18 semaines. Le temps additionnel va à la construction du pipeline de données, l’infrastructure d’inférence par lots et la conception de la couche de stockage. Équipe d’ingénierie des données solide? Le bas de la fourchette. Les pipelines de données sont une lacune? Planifiez le haut de la fourchette.
Déploiement de modèle personnalisé (Patron 3) : 16-24 semaines. L’affinage nécessite des données d’entraînement étiquetées (les collecter prend du temps), une infrastructure d’entraînement, l’évaluation du modèle et du travail de pipeline de déploiement. Les équipes avec une infrastructure ML existante avancent plus vite. Les équipes qui la construisent pour la première fois devraient budgéter le haut de la fourchette.
Plateforme IA multi-fonctionnalités : 6-12 mois pour livrer trois fonctionnalités en production. La première fonctionnalité prend le plus de temps. La deuxième prend 60 % du temps. La troisième, 40 %. La composition se produit parce que les décisions d’architecture, les cadres d’évaluation et les connaissances de l’équipe se reportent.
Ces délais supposent du personnel dédié. Si l’implémentation IA est en concurrence avec d’autres priorités de la feuille de route pour les mêmes ingénieurs, multipliez tout par 1,5 à 2x.
Le travail après le lancement
Livrer la fonctionnalité est le point médian, pas la ligne d’arrivée. Les fonctionnalités IA nécessitent un investissement continu que les fonctionnalités logicielles traditionnelles ne requièrent pas.
Surveillance de la dérive du modèle. Les données que vos utilisateurs génèrent changent au fil du temps. Un modèle de classification entraîné sur des données de 2025 performera moins bien sur des données de 2027. Surveillez la qualité des sorties continuellement et réentraînez ou réajustez les prompts selon un calendrier défini.
Versionnage des prompts et modèles. Chaque changement de prompt, échange de modèle ou ajustement de paramètre doit être versionné et testé contre votre harnais d’évaluation avant le déploiement en production. Traitez les changements de prompt comme des changements de code : révisés, testés, déployés via un pipeline.
Gestion des coûts. Les coûts d’API de modèles fondamentaux évoluent avec l’utilisation. Une fonctionnalité qui coûte 200 $/mois pendant le déploiement limité pourrait coûter 15 000 $/mois à pleine échelle. Intégrez la surveillance des coûts dans votre infrastructure IA dès le premier jour. Connaissez votre coût par requête et vos dépenses mensuelles projetées à chaque palier d’utilisation.
Fermeture de la boucle de rétroaction. Les données de rétroaction que vous capturez n’ont de valeur que si elles alimentent l’amélioration. Définissez une cadence mensuelle pour examiner les données de rétroaction, mettre à jour les jeux de données d’évaluation et implémenter des améliorations ciblées.
Les équipes qui traitent les fonctionnalités IA comme « livrer et oublier » voient la qualité se dégrader en six mois. Celles qui budgètent 15-20 % du temps d’ingénierie continu pour la maintenance des fonctionnalités IA voient la qualité s’améliorer continuellement. C’est la différence entre l’IA comme gadget et l’IA comme avantage concurrentiel.
Passez à l’action
Si votre produit n’a toujours pas d’IA dans la feuille de route, commencez par la phase d’évaluation. Deux semaines d’analyse structurée vous en diront plus que six mois de débat interne. Notre page de services-conseils en IA décrit comment on mène ce processus, mais le cadre de ce guide fonctionne que vous le meniez en interne ou avec du soutien.
Si vous avez déjà tenté une fonctionnalité IA et qu’elle a calé, associez votre expérience aux modes d’échec ci-dessus. La plupart des implémentations bloquées échouent à l’un de cinq points spécifiques. La solution n’est généralement pas « essayer plus fort » mais « restructurer l’approche ».
Les entreprises qui prennent de l’avance en ce moment ne sont pas celles avec le plus de fonctionnalités IA. Ce sont celles avec un processus reproductible pour livrer des fonctionnalités IA qui fonctionnent. La discipline d’implémentation est le différenciateur. Tout le reste est une démo.
Prêt à passer de la stratégie à la production? Parlons de votre feuille de route d’implémentation IA.