Somewhere between “we need an AI strategy” and “we shipped an AI feature,” most product teams lose their way. The gap isn’t ambition. It’s implementation.
We’ve embedded into dozens of product teams over the past two years. Some had clear AI roadmaps. Some had nothing but a board mandate and a vague sense of urgency. The pattern we see over and over: teams that succeed treat AI implementation as an engineering discipline. Teams that fail treat it as a project with a deadline and a demo.
This guide covers the implementation framework we use when we embed into product teams. Same approach whether the goal is adding intelligence to an existing product or building a new AI-native feature from scratch.
Why most AI implementations fail
Before the framework, the failure modes. These aren’t hypothetical. They come from real engagements where we were brought in after the first attempt stalled.
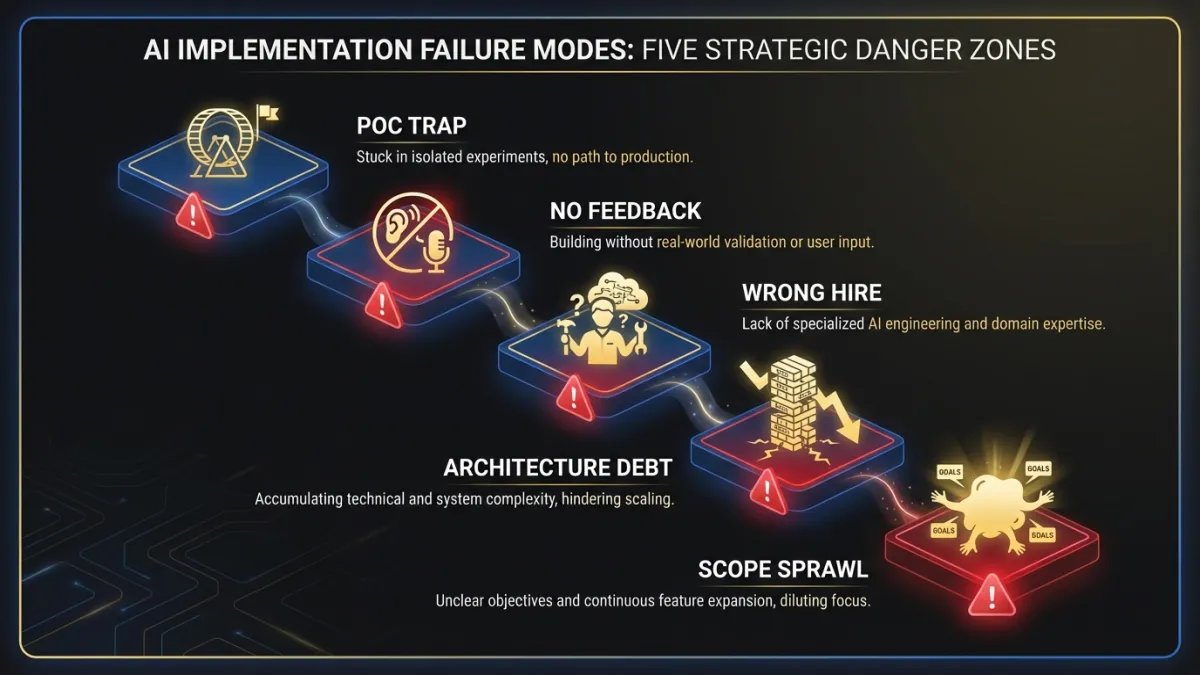
Failure mode 1: The proof-of-concept trap
A small team builds a POC in two weeks. The demo looks impressive. Leadership greenlights production. Six months later, the team is still fighting edge cases, latency issues, and data quality problems that didn’t exist in the controlled demo environment.
The gap between POC and production in AI is wider than in traditional software. A classification model that works on 500 curated examples behaves differently on 500,000 messy real-world inputs. A language model that generates clean output in a Jupyter notebook hallucinates when users feed it unexpected prompts. POCs prove that AI can do something. They say nothing about whether it can do it reliably, at scale, for real users.
Failure mode 2: No feedback architecture
The team ships an AI feature. It works. Mostly. But there’s no mechanism to measure “mostly.” No way to capture when the model’s output was wrong. No pipeline to turn user corrections into training signal. No alerts when confidence scores drop below acceptable thresholds.
Six months in, accuracy has degraded because the underlying data distribution shifted. Nobody noticed until customer complaints spiked. The team scrambles, but they have no labeled dataset of failures because they never built the instrumentation.
Failure mode 3: Hiring for the wrong role
The VP of Engineering posts a job for a “Senior Machine Learning Engineer.” The role asks for PyTorch expertise, published papers, and experience with transformer architectures. They hire someone brilliant. That person spends their first three months asking for labeled training data that doesn’t exist, a GPU cluster the company can’t afford, and a data pipeline that would take a team of three another six months to build.
The actual need was a senior software engineer with experience integrating foundation model APIs, building evaluation frameworks, and designing graceful degradation when the AI component fails. A different skill set entirely.
Failure mode 4: Architecture as afterthought
The team picks a model, builds a feature, and ships it inside the existing monolith. The AI inference call adds 2.3 seconds to a workflow that previously took 400 milliseconds. Users hate it. The team tries to optimize but the model is coupled to the request-response cycle with no async path. Re-architecting means rewriting half the feature.
AI features have different performance characteristics than traditional software. They need different architectural treatment. Bolting AI into an existing architecture without planning for latency, fallbacks, and async processing creates technical debt that’s expensive to unwind.
Failure mode 5: Scope without sequence
Leadership approves six AI features across three product areas. The team tries to build all of them in parallel. Each feature needs its own data pipeline, evaluation framework, and integration work. Engineering bandwidth fragments. Nothing ships for eight months. The board loses confidence. The AI initiative gets quietly downgraded.
One feature, shipped well, with instrumentation and feedback loops, teaches the team more than six features scoped in PowerPoint.
The implementation framework
Five phases. Sequential, but with parallel work within each phase. Total timeline from phase one through a production feature: 8 to 16 weeks, depending on data readiness and product complexity.

Phase 1: Assessment (weeks 1-2)
Before writing any code, answer four questions.
What user problem does AI solve? Not “where can we use AI?” but “where are users spending time on tasks that machines handle better?” If you’ve already done the work in an AI product strategy, this step is straightforward. If not, start there.
What data exists today? Inventory your data assets with specificity. “We have customer data” isn’t an answer. “We have 14 months of support ticket text, categorized by issue type, with resolution timestamps and customer satisfaction scores” is an answer. The quality and structure of your existing data determines what’s feasible now versus what requires a data collection phase first.
What’s the acceptable error rate? AI features are probabilistic. They will be wrong sometimes. Defining “how wrong is too wrong” before building anything forces honest conversations about user expectations. A product recommendation that’s irrelevant 20% of the time is fine. A medical dosage suggestion that’s wrong 1% of the time is not.
What happens when the AI is wrong? Every AI feature needs a fallback. What does the user see? Can they correct the output? Does the correction get captured as training signal? The fallback experience is as important as the primary experience.
Document the answers. Share them with the team. These four questions eliminate more wasted effort than any technical decision.
Phase 2: Pilot selection (weeks 2-3)
Pick one feature. Not two. One.
The ideal pilot has five characteristics:
- High frequency. Users encounter this workflow daily or multiple times per week. High frequency means faster feedback loops and more measurable impact.
- Tolerance for imperfection. The feature is additive, not a replacement. The user can ignore or override the AI output without breaking their workflow. Auto-suggestions, draft generation, and smart defaults all fit this pattern.
- Existing data. You can build a first version without a new data collection effort. Foundation model APIs with good prompt engineering can handle many use cases without custom training data.
- Clear success metric. You can measure whether the feature works with existing analytics. Time saved per task, adoption rate, override rate, or task completion rate.
- Contained blast radius. If the feature fails or degrades, the impact is limited. A bad suggestion in a text field is annoying. A bad calculation in a billing workflow is a crisis.
The team will want to pick the most impressive feature. Resist that. Pick the one you can ship in four weeks, measure in two more, and learn from. The learning compounds into every subsequent feature.
Phase 3: Architecture decisions (weeks 3-5)
Three architectural patterns cover 80% of AI features in existing products. Your pilot will use one of these, and the choice shapes everything downstream.
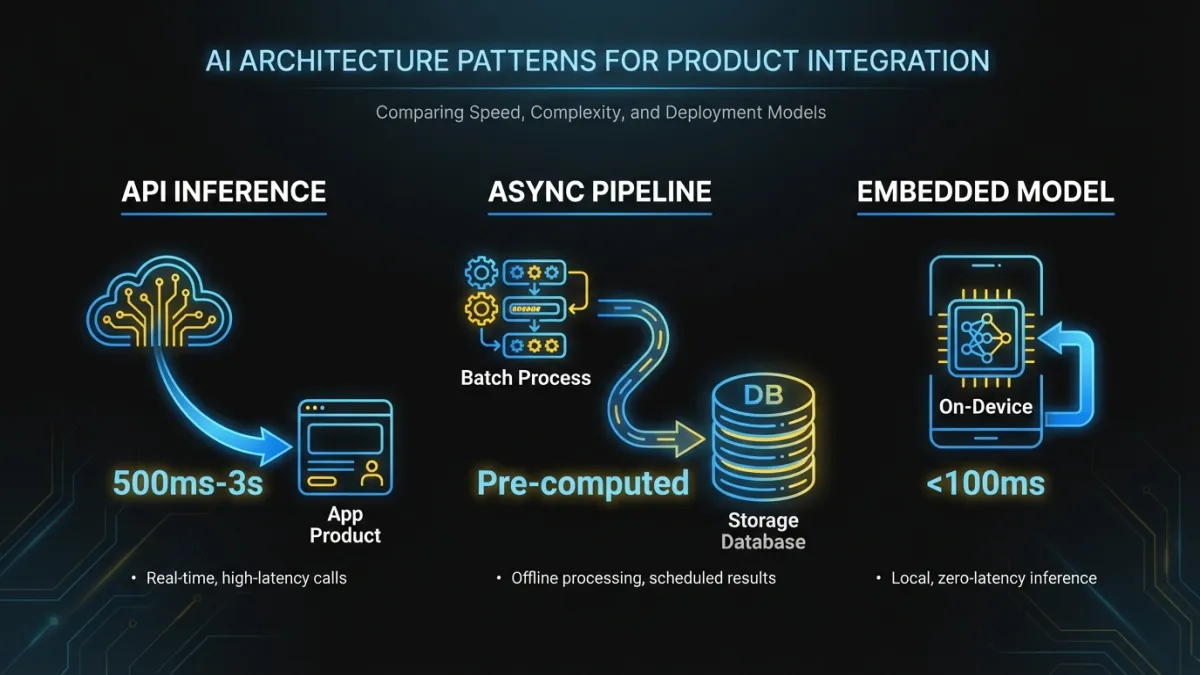
Pattern 1: API-mediated inference. Your product calls a foundation model API (OpenAI, Anthropic, Google, or a self-hosted model behind an API gateway) at the point where AI input is needed. The model processes the request and returns a result your application formats and displays.
Best for: text generation, summarization, classification, extraction, conversational features. Any task where a foundation model performs well with prompt engineering and your product’s context.
Watch out for: latency (API round trips add 500ms-3s depending on output length), cost at scale (per-token pricing adds up with high-frequency features), and vendor dependency.
Pattern 2: Async pipeline with pre-computation. Instead of calling a model in the request path, you run inference as a background job. Results are pre-computed and stored, then served instantly when the user needs them.
Best for: recommendations, similarity matching, content categorization, anomaly detection. Any feature where the input data doesn’t change at the moment the user requests the output.
Watch out for: staleness (pre-computed results may be outdated by the time the user sees them), storage costs, and pipeline complexity.
Pattern 3: Embedded model with edge inference. A smaller, fine-tuned model runs inside your application infrastructure. No external API calls. The model is deployed as a microservice or sidecar process.
Best for: features requiring sub-100ms latency, privacy-sensitive use cases where data can’t leave your infrastructure, or specialized tasks where a fine-tuned smaller model outperforms a general-purpose large model.
Watch out for: operational overhead (you’re now running ML infrastructure), the need for fine-tuning pipelines, and the skill set required to maintain deployed models.
Most teams should start with Pattern 1. Minimal operational overhead. You can ship in weeks instead of months. And you learn what matters before investing in infrastructure. Move to Pattern 2 or 3 when usage data tells you latency, cost, or data sensitivity requires it.
For products exploring agentic AI architectures, a fourth pattern emerges: orchestrated multi-step agents that chain model calls with tool use. That’s a more advanced implementation that deserves its own treatment, but the same sequencing principles apply. Start simple. Add complexity when the simpler approach provably falls short.
Regardless of pattern, build three things into the architecture from day one:
A fallback path. When the AI component fails (and it will), the user experience degrades gracefully. Show the non-AI version. Display a “generating” state. Never show a spinner that hangs for 30 seconds.
An evaluation harness. Automated tests that run a fixed set of inputs through your AI pipeline and compare outputs against expected results. This is your regression suite. Every time you change a prompt, swap a model, or update a pipeline, the harness tells you whether quality improved or regressed.
A feedback capture mechanism. Thumbs up/down, explicit corrections, implicit signals (did the user accept the suggestion or delete it?). This data becomes your most valuable training asset over time.
Phase 4: Team structure (parallel with Phase 3)
You need three capabilities on the implementation team. The question is how you staff them.
AI engineering. The people who design prompts, build evaluation frameworks, select models, and optimize inference. This isn’t traditional ML research. It’s applied AI engineering: making models work reliably inside a product context.
Product engineering. The people who integrate the AI component into your existing product. They own the UI, the API contracts, the data flow, and the fallback paths. Ideally, the engineers who already own the feature area where AI is being added.
Data engineering. The people who build and maintain the data pipelines that feed the AI component. Input data preparation, feature extraction, feedback loop storage, and evaluation dataset management.
Three staffing models, with honest tradeoffs:
Hire. Full-time AI engineers on your team. Best long-term investment, but senior AI engineers take 4-6 months to hire in the current market. If your timeline is 8-16 weeks, hiring isn’t your Phase 1 strategy. It’s your Phase 3 strategy for features two and three.
Embed. Bring in external AI engineers who work inside your team, use your tools, attend your standups, and ship in your release cycle. Faster than hiring. The embedded engineers transfer knowledge to your team as they build. When they leave, your team is stronger than before. This is what we do, so take the recommendation with appropriate context. The reason we built our business around this model is because we saw it work repeatedly while the alternatives didn’t.
Outsource. Hand the AI feature to an external agency who builds it separately and delivers it for integration. Fastest to start, but the handoff creates problems. The agency doesn’t know your codebase deeply. The integration surface is where bugs live. And when the feature needs iteration (it will), you’re back to the agency’s timeline and priorities.
Most teams we work with use a hybrid: embedded AI engineers for the first two features, then transition to a mix of embedded and hired as the internal team ramps up. The worst outcome is outsourcing the first feature, getting something that works in isolation, and then struggling to maintain it with a team that didn’t build it.
Phase 5: Rollout and measurement (weeks 6-16)
Ship to a small group first. 5-10% of users, or a specific customer cohort that opted in. The goal isn’t a beta test. It’s production validation with real usage patterns at controlled scale.
Weeks 6-8: Limited rollout. Ship the feature behind a feature flag. Monitor four metrics:
- Adoption rate. What percentage of eligible users interact with the feature? Below 15% after two weeks means the feature is hard to discover or not compelling.
- Override rate. How often do users reject or modify the AI output? Above 40% means the model isn’t good enough yet. Below 10% and you might be measuring wrong (users may not know they can override).
- Latency. P50 and P99 response times for the AI component. If P99 exceeds 4 seconds for an inline feature, you need async processing or a faster model.
- Error rate. How often does the AI component fail entirely? Target below 2% for production.
Weeks 8-12: Iterate and expand. Use limited rollout data to improve prompts, adjust thresholds, fix edge cases. Expand to 25%, then 50% of users. Each expansion is a decision point: do the metrics hold at higher scale?
Weeks 12-16: General availability. Full rollout with monitoring dashboards, alerting on metric regressions, and a defined on-call process for AI-specific incidents.
The timeline isn’t arbitrary. Eight weeks from code to limited rollout is aggressive but achievable for a Pattern 1 implementation with good data. Pattern 2 and 3 add 4-6 weeks for infrastructure work. If someone promises a production AI feature in two weeks, they’re either describing a POC or they’ve done this exact implementation before with the same architecture.
Build vs. buy vs. embed: a decision framework
This question comes up in every AI implementation. The answer depends on where AI sits in your value chain.
Build when AI is your product’s core value. If AI capability is what your customers pay for, and the quality of that AI is your competitive differentiation, build it. Own the models, the training data, the evaluation framework. An AI-native search product should not depend entirely on a third-party API for its core ranking algorithm.
Buy when AI is infrastructure. If you need AI capability that’s not differentiating but necessary, buy it. Spam filtering, content moderation, translation, OCR. These are solved problems with good commercial solutions. Building your own spam filter is not a strategic use of engineering time.
Embed when AI is a new capability your team doesn’t have. If your product needs AI features and your team doesn’t have the experience to implement them well, embedding external expertise gets you to production faster than hiring or outsourcing. The embedded team builds the first features while your existing engineers learn alongside them. By the second or third feature, your team can lead the work.
The lines blur. A feature might start as “buy” (using a foundation model API) and evolve to “build” (fine-tuning your own model on proprietary data) as usage grows and differentiation matters more. That’s fine. The implementation framework is designed for this evolution. Pattern 1 today, Pattern 3 in six months, with evaluation harnesses ensuring quality through the transition.
If you’re evaluating where to start, the guide to adding AI to existing products covers the product-level decisions in more depth.
What success looks like at each stage
Teams often measure AI implementation success with a single binary: did the feature ship? That misses the point. AI features are living systems. Success has stages.
After Phase 1-2 (Assessment + Pilot Selection): You have a documented AI roadmap with one clearly defined pilot feature. The team agrees on the success metric and acceptable error rate. There’s no code yet, and that’s correct. Skipping this phase is the most common source of wasted engineering effort.
After Phase 3 (Architecture): The AI component runs in a staging environment. The evaluation harness passes with output quality above your defined threshold. The fallback path works. Feedback capture is instrumented. You haven’t touched the production UI yet.
After limited rollout (Week 8): You have real usage data. You know the adoption rate, override rate, and latency distribution. You’ve identified the top five edge cases and fixed at least three. You can answer “is this feature worth expanding?” with data, not opinion.
After GA (Week 16): The feature runs in production for all users. Monitoring and alerting are active. The team has a playbook for model degradation. Feedback data is accumulating. You have a backlog of improvements ranked by impact. And critically, you have a team that knows how to do this again for the next feature.
After 6 months: The feedback loop has produced measurable quality improvement. You’ve shipped a second AI feature in half the time it took to ship the first. The team debates architectural patterns from experience, not theory. AI implementation is an engineering capability the organization owns, not a special project that required outside help.
Timeline expectations, grounded in reality
Executive teams frequently underestimate AI implementation timelines. Here’s what we see across real engagements.
Foundation model API integration (Pattern 1), single feature: 8-12 weeks from kickoff to GA. This assumes data exists, the team is staffed, and the feature is well-scoped. First four weeks: assessment, architecture, staging. Next four: rollout and iteration. Final four: expansion and hardening.
Async pipeline with pre-computation (Pattern 2): 12-18 weeks. Additional time goes to data pipeline construction, batch inference infrastructure, and storage layer design. Strong data engineering team? Lower end. Data pipelines are a gap? Plan for the upper end.
Custom model deployment (Pattern 3): 16-24 weeks. Fine-tuning requires labeled training data (collecting it takes time), training infrastructure, model evaluation, and deployment pipeline work. Teams with existing ML infrastructure move faster. Teams building it from scratch should budget for the upper end.
Multi-feature AI platform: 6-12 months to ship three production features. The first feature takes the longest. The second takes 60% of the time. The third takes 40%. The compounding happens because architecture decisions, evaluation frameworks, and team knowledge carry forward.
These timelines assume dedicated staffing. If AI implementation competes with other roadmap priorities for the same engineers, multiply everything by 1.5 to 2x.
The work after the launch
Shipping the feature is the midpoint, not the finish line. AI features require ongoing investment that traditional software features don’t.
Model drift monitoring. The data your users generate changes over time. A classification model trained on 2025 data will perform worse on 2027 data. Monitor output quality continuously and retrain or re-prompt on a defined schedule.
Prompt and model versioning. Every prompt change, model swap, or parameter adjustment should be versioned and tested against your evaluation harness before production deployment. Treat prompt changes like code changes: reviewed, tested, deployed through a pipeline.
Cost management. Foundation model API costs scale with usage. A feature that costs $200/month during limited rollout might cost $15,000/month at full scale. Build cost monitoring into your AI infrastructure from day one. Know your per-request cost and projected monthly spend at each usage tier.
Feedback loop closure. The feedback data you capture is only valuable if it flows back into improvement. Define a monthly cadence for reviewing feedback data, updating evaluation datasets, and implementing targeted improvements.
Teams that treat AI features as “ship and forget” watch quality degrade over six months. Teams that budget 15-20% of ongoing engineering time for AI feature maintenance see quality improve continuously. That’s the difference between AI as a gimmick and AI as a competitive advantage.
Get started
If your product still has no AI on the roadmap, start with the assessment phase. Two weeks of structured analysis tells you more than six months of internal debate. Our AI advisory services page outlines how we run that process, but the framework here works whether you run it internally or with support.
If you’ve already attempted an AI feature and it stalled, map your experience to the failure modes above. Most stalled implementations fail at one of five specific points. The fix is usually not “try harder” but “restructure the approach.”
The companies pulling ahead right now aren’t the ones with the most AI features. They’re the ones with a repeatable process for shipping AI features that work. Implementation discipline is the differentiator. Everything else is a demo.
Ready to move from strategy to production? Let’s talk about your AI implementation roadmap.