Key Takeaway
One two-question test separates AI SR&ED documentation that survives a CRA audit from documentation that fails: can every technical claim be traced to a source artifact, or was it generated from a prompt?
A CTO at a Toronto SaaS company sent us this question in April: “We are using an AI tool for SR&ED prep. How do I tell my CFO whether it’s the kind that will hold up in an audit, or the kind that will not?”
That’s the right question. There’s a structural answer, and it doesn’t require evaluating each vendor on a case-by-case basis. There is a single test that distinguishes AI-prepped documentation that survives a CRA review from documentation that fails one. The test is architectural, and the difference shows up in the first paragraph of the T661.
This article describes the test, walks two concrete examples, and shows what each architecture produces when CRA’s review process actually runs. If you’re sending this to your CFO before a sign-off conversation, the second half is what they need to read. The deeper treatment of how the categories work is in our cornerstone on AI-prepared SR&ED claims.
What Is the Capture-vs-Generation Test?
AI tools for SR&ED prep split on one architectural axis: capture or generation. The two approaches produce documentation with very different audit profiles. CRA reviewers can tell the difference, and so can the AI screening tools that now run on incoming T661 narratives.
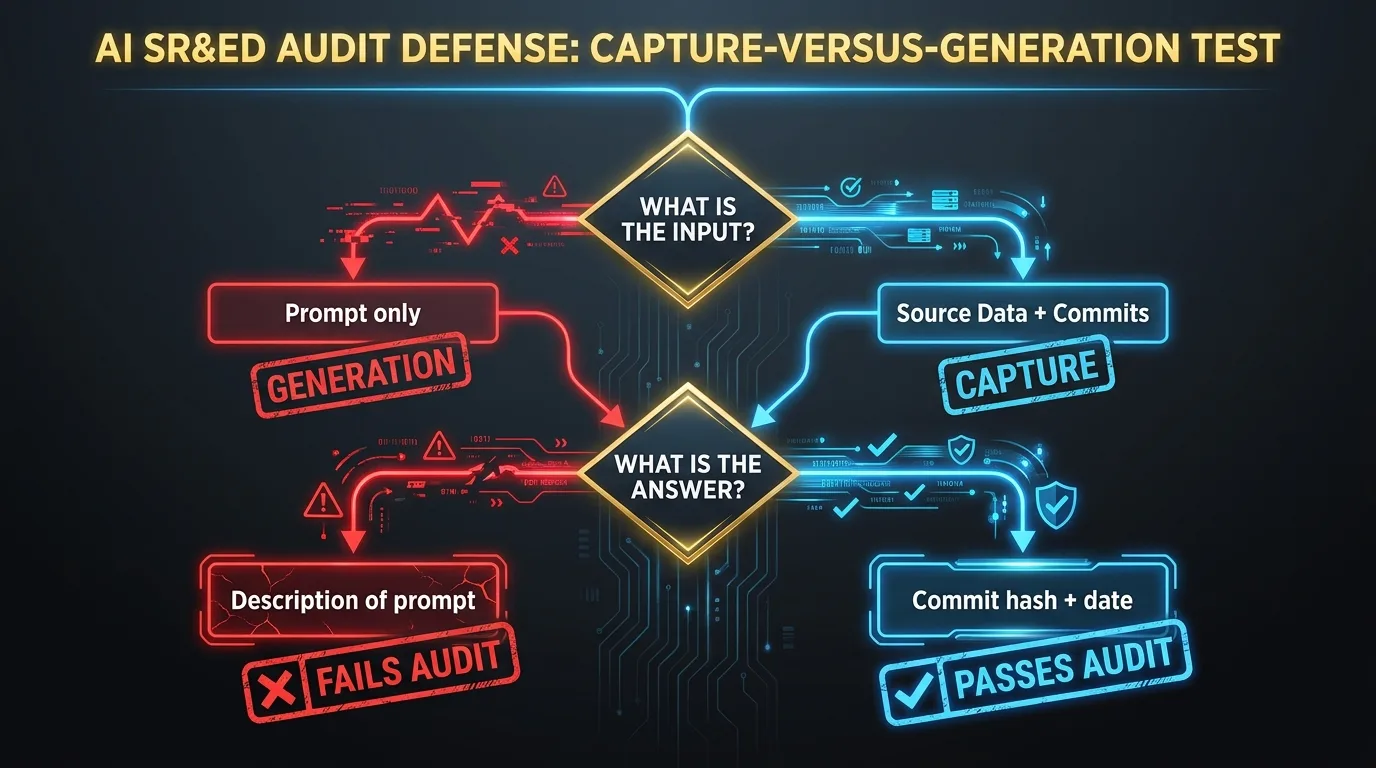
The test has two questions.
First: what is the input to the language model when it produces the narrative?
If the input is a prompt and a project name, the tool generates. If the input is structured evidence pulled from your real source data (git history, pull requests, issue tracker entries, tagged Slack messages), the tool captures.
Second: when CRA asks where a specific assertion in the narrative came from, what is the answer?
If the answer is a description of the prompt, the documentation is generation. If the answer is a specific commit hash, a pull request number, or a ticket ID with a date, the documentation is capture.
The two questions are the same question stated from two directions. Generation is reconstruction at filing time. Capture is contemporaneous documentation tied to source artifacts. CRA’s 2026 review standard, anchored in the new Pre-Claim Approval program, was built around the second category and not the first.
Why Does This Test Matter in 2026?
CRA launched Pre-Claim Approval on April 1, 2026. The program lets a claimant submit a planned project for confirmation of eligibility before filing. The trade-off is that the submission has to include contemporaneous documentation, defined in CRA’s own materials as records created during the work itself, not reconstructed at filing time.
The contemporaneous-evidence requirement is the substantive shift. For most of the program’s history, technical narratives were produced at filing time, sometimes months after the underlying work. The narratives described the work accurately enough to file. They were not, by CRA’s 2026 definition, contemporaneous. The new program does not accept reconstruction. A generation-based AI tool produces filing-time prose by definition. A capture-based AI tool produces contemporaneous documentation by default, because it documents the work as the work happens.
CRA is also running AI on the review side. The 2025-26 Departmental Plan describes the agency “enhancing its use of technology, including machine learning and artificial intelligence (AI), to detect non-compliance and other suspicious activities.” For SR&ED reviewers, that means an AI screen now runs on incoming T661 narratives and flags the patterns associated with low-quality or fabricated documentation: generic AI prose, missing source linkage, technological-uncertainty claims without articulated knowledge gaps, project descriptions that don’t match the codebase complexity reported elsewhere in the file.
The Tax Court of Canada reinforced the contemporaneous-documentation expectation in DAZZM Inc. v. The King, 2024 TCC 129, where the court denied a SR&ED claim in part because the documentation submitted at the review stage had been substantially reconstructed after the fact. The case is one of several over the past five years where the contemporaneous quality of the documentation, not the eligibility of the underlying work, decided the outcome.
Example 1: Generation in Practice
A mid-market Vancouver software company runs a SR&ED claim through a generation-based AI tool. The tool ingests a brief project description provided by the CTO and a list of project names from the engineering manager. It produces a T661 narrative that reads cleanly and follows CRA’s three-part structure. Here is a short fragment, lightly anonymized:
The team developed advanced machine learning algorithms to address performance bottlenecks in the data pipeline. We investigated several state-of-the-art approaches and evaluated their effectiveness against existing solutions. The systematic investigation involved iterative experimentation with novel architectures, and the project achieved technological advancement in the area of distributed data processing.
The prose is fluent. It hits the three-part structure. A CFO reading it cold would have no obvious reason to flag it. A CRA Research and Technology Advisor reading it has several reasons.
The phrase “advanced machine learning algorithms” is generic: it doesn’t tie to a specific algorithm or a specific failure mode. “State-of-the-art approaches” is generic: it doesn’t name the approaches. “Novel architectures” is generic: the narrative doesn’t describe what was novel about them. “Technological advancement in the area of distributed data processing” is generic: it doesn’t articulate the knowledge gap that was closed or the published baseline the work moved beyond.
When the CRA reviewer asks the company to produce the source artifacts behind “iterative experimentation with novel architectures,” the company has a problem. The narrative was produced from a prompt. The prompt did not include source data. The engineering team has commits and pull requests and tickets, but they have to find them after the question is asked. Some of the work the narrative describes did happen. Some did not happen quite the way the narrative implies.
The screening AI on the CRA side has already flagged the file before the human reviewer picks it up. The file moves to a fuller review. The fuller review produces an adjustment, not because the underlying work was ineligible, but because the documentation cannot defend the claim it makes.
Example 2: Capture in Practice
A second company, similar size and stack, runs the same claim through a capture-based AI tool. The tool reads the company’s git history, Jira tickets, and tagged Slack messages directly. It does not write a narrative from a prompt. It structures the evidence into CRA-aligned categories. Each captured item carries its source artifact, its author, and its date.
The output for the same project might read:
In Q1 2026, the team investigated whether a custom hierarchical sharding scheme could maintain sub-150ms p95 query latency on the analytics service under concurrent reads exceeding 12,000 requests per second. Existing approaches (consistent hashing per Karger et al., range partitioning per the Postgres documentation, and the multi-leader replication pattern described in internal architecture doc, Jira CHR-2189) were inadequate for the access pattern, which combined high write contention on a small set of hot keys with low write contention on the long tail. The team evaluated four approaches over six weeks: a hot-key promotion strategy (commits 4a7f2c1 through 8e1a4b3, PR #482), a two-tier cache with write-through invalidation (commits c2d8f01 through 6b9e2c4, PR #496), a custom sharding scheme based on access-pattern clustering (commits 19c4d3a through 4e7f8a2, PR #507), and a hybrid of the two-tier cache and the custom sharding (commits 7a3b9c1 through 2f6e0d8, PR #511). The fourth approach achieved p95 latency of 142ms at 13,400 RPS in load testing on 2026-02-14, documented in Jira CHR-2247. The first three failed: hot-key promotion degraded long-tail performance, two-tier cache produced inconsistency under concurrent writes, custom sharding alone could not handle the hot-key contention.
The prose is denser. Every claim ties to a source artifact. The technological uncertainty is articulated specifically. The systematic investigation is articulated specifically: four approaches, dated, with the failure modes of three documented. The technological advancement is articulated specifically: a hybrid architecture that achieved a measured target the prior art could not.
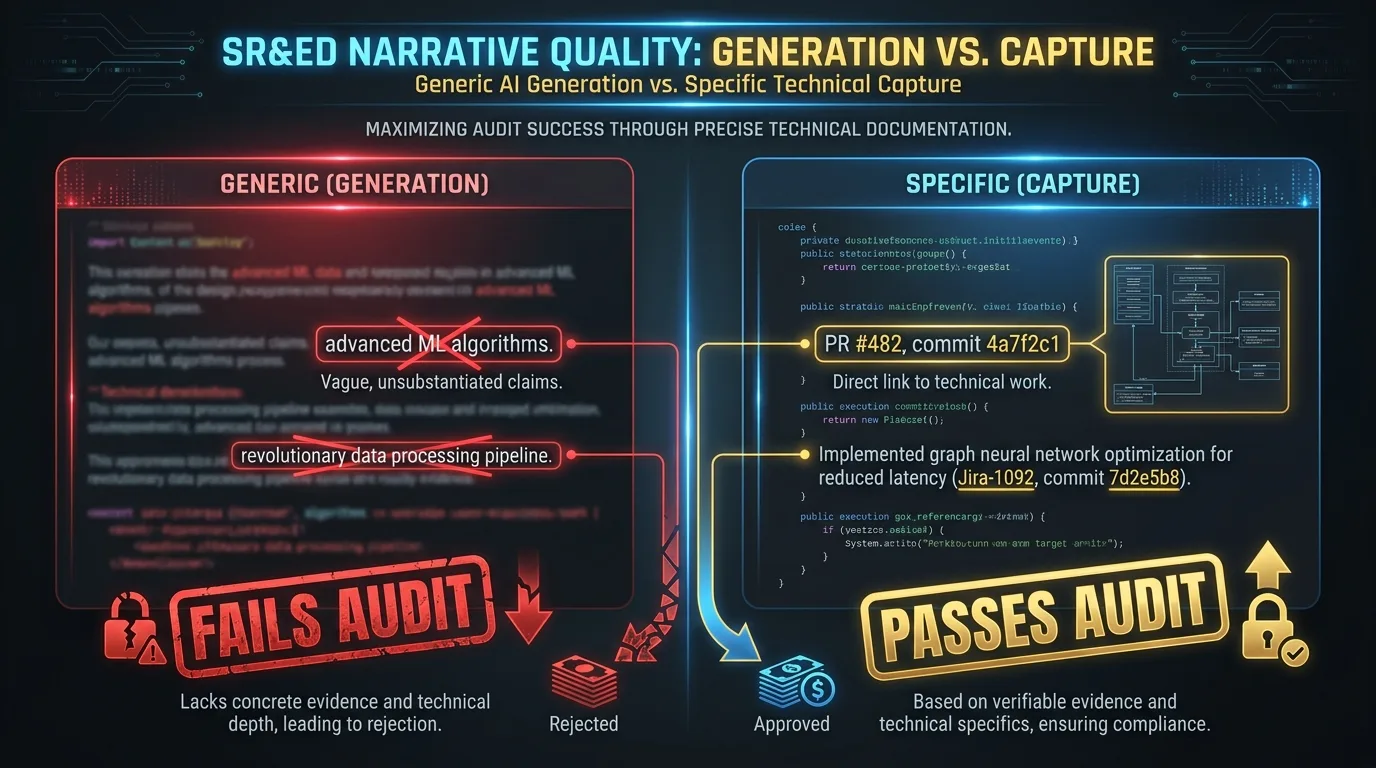
When the CRA reviewer asks where the “two-tier cache produced inconsistency under concurrent writes” claim came from, the answer is a single click that lands on PR #496 with the relevant test results in the linked Jira ticket. The screening AI does not flag the file. The technical advisor reads it without reaching for the credibility-failure heuristics. The technical interview, if one happens, talks to engineers who wrote the commits. They can speak to the work because they did it.
The two examples describe the same underlying engineering work. The first is generation. The second is capture. Both took similar time to produce. Only one functions as audit defense.
What Are CRA Reviewers Actually Looking For?
The CRA Claim Review Manual is publicly available, and the procedural sequence has not changed in substance for years. The Research and Technology Advisor walks the file through five things in order: a clear project description, the technological uncertainty being investigated, the systematic investigation conducted to address it, the technological or scientific advancement achieved or sought, and evidence of the work actually performed.
What has changed is the calibration. In 2026, the reviewer expects specificity at every stage. The “technological uncertainty” section needs to articulate what was not knowable from existing methods, not just describe the goal. The “systematic investigation” section needs to describe what was tried, what was observed, what was changed, and what was concluded. The “technological advancement” section needs to identify the knowledge gap that was closed and the prior art the work moved beyond. The “evidence” section needs to point at dated artifacts.
The screening AI on the review side is calibrated to the same expectation. It’s not literally checking whether your narrative was written by a model. It’s checking for the patterns that generation-based tools tend to produce: low specificity, generic phrasing, missing source linkage, technological-uncertainty language without articulated knowledge gaps. Capture-based output is empirically different prose. The screen does not reach for the credibility-failure heuristics because the heuristics do not match what’s in the file.
How Do You Run This Test on Your Own Documentation?
Pick one project from the past quarter. Have your tool or consultant produce the T661 narrative for it. Read the narrative. Then pick a paragraph at random and ask: “Where in our git history or ticket tracker did this paragraph come from?”
The right answer is a single click that lands on the source artifact. The tool should demonstrate the trace, not describe it. If the answer is “we generated this from the project description we provided,” the tool is generation. If the answer involves opening the codebase manually to find the evidence after the fact, that is reconstruction. If the answer is a commit hash and a date, that is capture.
The cold-read test is also useful. Have your engineering lead read the narrative without context. Ask: does this sound like work your team actually did, or does it sound like work that could have been done by anyone in the same vertical? Specific technical detail (specific frameworks, specific datasets, specific failure modes you investigated) is the signal of capture. Generic phrasing (“the team developed advanced ML algorithms,” “we leveraged cutting-edge approaches to solve performance problems”) is the signal of generation. The cold-read takes less than five minutes.
For finance leaders running the test on a vendor or consultant, the first question is the same as this article’s: where does every technical claim in our T661 narratives come from?
What Should You Tell Your CFO?
If you’re a CTO sending this to your CFO before a sign-off conversation, the relevant points are the following.
Generation-based AI documentation does not satisfy the contemporaneous-evidence requirement of CRA’s Pre-Claim Approval program. The narrative is produced at filing time, which is what “not contemporaneous” means in CRA’s terms. The screening AI on the review side is calibrated against the patterns generation produces. CPA Canada has stated on the record that responsibility for AI-assisted filings sits with the filer regardless of how the AI was used.
Capture-based AI documentation does satisfy the requirement. The evidence is the source data. The narrative is structured from the artifacts, not generated from a prompt. The provenance is built into every claim. Under audit, the response to “where did this come from” is a commit hash, not a description of the prompt.
The cost difference between the two architectures is real but secondary. A claim that gets disallowed costs more than a tool that costs more. The math on a $400,000 claim with a 30% disallowance is a $120,000 clawback before professional fees and interest. That is the comparison that matters.
FAQ
How do I tell if my current SR&ED tool is capture-based or generation-based?
Ask one question: where does every technical claim in our T661 come from? If the answer involves opening the codebase to find evidence after the fact, you’re generating. If the answer is a commit hash or ticket ID, you’re capturing. The CRA SR&ED review process article explains exactly which step in a review this distinction becomes visible.
What is “contemporaneous documentation” in CRA’s terms?
CRA defines contemporaneous documentation as records created during the work itself, not reconstructed at filing time. This includes commits, pull requests, issue tracker tickets, design notes, and test results dated to the period when the work was done. A narrative produced from a prompt at filing time is the opposite of contemporaneous, regardless of how accurate it is.
Is capture-based AI documentation more expensive to produce?
Not after accounting for audit risk. A 30% adjustment on a $400,000 claim is $120,000 before professional fees and interest. Most capture-based tools cost a fraction of that per year. The math favors capture for any company with a non-trivial claim.
Ready to see capture-based documentation on your own repository? Book a 25-minute demo. We’ll connect Lucius to a sample repo and trace a generated paragraph back to the commit it came from, in front of you.