Une entreprise Série B avec 120 employés, 40 ingénieurs et 15 000 clients payants a un problème d’IA bien particulier. Elle a assez de données et de clients pour que l’IA ait une vraie valeur. Elle a aussi zéro ingénieur ML, une feuille de route surchargée, et un PDG qui vient d’annoncer au conseil que des fonctionnalités IA arrivent au T3.
C’est le piège IA des scale-ups. Vous êtes assez gros pour que l’IA compte, trop petit pour la doter en personnel, et trop occupé pour que chaque expérience IA ne rivalise pas avec des fonctionnalités que vos clients paient déjà.
La plupart de ces entreprises finissent dans ce qu’on appelle le purgatoire des pilotes. Quelqu’un construit un prototype dans un notebook Jupyter. La démo impressionne. La direction s’emballe. Puis rien ne sort en production. La distance entre un prototype fonctionnel et une fonctionnalité en production est plus longue que prévu.
Pourquoi les scale-ups se retrouvent coincées
Les startups ont une version plus simple de ce problème. Moins d’utilisateurs, une infrastructure plus simple, des fondateurs qui peuvent pivoter toute la feuille de route vers l’IA sur un coup de tête. Les grandes entreprises aussi s’en tirent mieux. Elles peuvent embaucher une équipe ML de 10 personnes, créer une division IA dédiée et attendre 18 mois pour des résultats.
Les scale-ups n’ont aucun de ces luxes. Trois contraintes rendent l’exécution IA particulièrement difficile à ce stade.
Contrainte 1 : L’écart de talent est réel, mais le délai d’embauche ne convient pas. Recruter un ingénieur ML senior prend 4 à 6 mois. En trouver un qui comprend aussi votre domaine produit prend encore plus de temps. D’ici à ce que le poste soit pourvu, le conseil a déjà demandé deux fois pourquoi les fonctionnalités IA ne sont pas en ligne.
Contrainte 2 : Chaque sprint a un coût d’opportunité. Une équipe d’ingénierie de 40 personnes dans une scale-up n’attend pas les bras croisés. Le backlog déborde de demandes clients, de travaux d’infrastructure et de fonctionnalités liées aux objectifs de revenus. Retirer deux ingénieurs de la feuille de route pour une expérience IA signifie que quelque chose d’autre ne sort pas. Ce compromis ne fonctionne que si le travail IA atteint vraiment la production.
Contrainte 3 : Les prototypes sont dangereusement convaincants. Un ingénieur compétent peut construire une fonctionnalité IA qui fonctionne en démo en deux semaines environ. GPT-4 ou Claude génèrent des résultats raisonnables pour la plupart des tâches textuelles. Le prototype a fière allure dans un fil Slack. La direction le voit fonctionner et suppose qu’il est terminé à 80 %. En réalité, il l’est à 20 %. Les 80 % restants sont la partie que personne n’a planifiée.
Ce qui se cache dans l’écart pilote-production
L’écart entre « ça fonctionne en démo » et « ça fonctionne en production » n’est pas un seul problème. Ce sont cinq défis d’ingénierie distincts que la plupart des scale-ups n’ont pas évalués.
Infrastructure d’évaluation. Comment savez-vous si la fonctionnalité IA fonctionne bien? Pas de manière anecdotique. Quantitativement. Vous avez besoin de métriques qui définissent le succès, d’un moyen de les mesurer automatiquement, et de références pour comparer. Pour une fonctionnalité de génération de texte, cela peut signifier construire un jeu de test étiqueté de plus de 500 exemples, définir des grilles de qualité et exécuter des évaluations automatisées à chaque changement de modèle. La plupart des pilotes n’ont rien de tout cela. L’équipe « regarde » les sorties et dit que ça a l’air correct.
Fiabilité du pipeline de données. Le prototype tire des données d’une base de staging et les traite dans un notebook. La production exige un pipeline qui gère les champs manquants, les changements de schéma, les limites de débit, et le moment inévitable où un client a 10 fois plus de données que vos cas de test ne le prévoyaient. Une fonctionnalité de recommandation qui marche sur 1 000 enregistrements et plante à 50 000 n’est pas une fonctionnalité de production.
Gestion des cas limites. Les fonctionnalités IA échouent de manières que le logiciel traditionnel ne connaît pas. Un modèle de classification entraîné sur des données en anglais produit n’importe quoi quand un client saisit du français. Une fonctionnalité de résumé hallucine un chiffre qui semble plausible mais qui est faux. Une fonctionnalité de recherche renvoie des données confidentielles d’un locataire à un autre parce que l’index de vecteurs n’était pas correctement délimité. Ce ne sont pas des scénarios hypothétiques. Ce sont les bogues qui apparaissent dans la première semaine après le lancement.
Surveillance et observabilité. Le logiciel traditionnel fonctionne ou renvoie une erreur. Les fonctionnalités IA se dégradent silencieusement. La qualité des réponses baisse parce que le modèle sous-jacent a été mis à jour. La latence augmente parce que la longueur du prompt a augmenté. La précision diminue sur un segment de clients spécifique parce que leur distribution de données a changé. Sans surveillance qui suit la qualité des sorties dans le temps, vous ne saurez pas que la fonctionnalité est défaillante tant que les clients ne vous le diront pas.
Transfert de connaissances de l’équipe. L’ingénieur qui a construit le prototype comprend la structure des prompts, le raisonnement derrière le choix du modèle et les contournements implémentés. Rien de tout cela n’est documenté. Quand cet ingénieur part en vacances ou passe à un autre projet, la fonctionnalité devient une boîte noire que personne ne peut déboguer ou améliorer.
Chacun de ces défis représente une semaine ou plus de travail d’ingénierie. Mis bout à bout, ils expliquent pourquoi le passage du pilote à la production prend généralement 3 à 5 fois plus de temps que le pilote lui-même.
Un cadre pratique pour amener l’IA en production
Voici la stratégie d’implémentation IA que nous appliquons avec les équipes d’ingénierie des scale-ups. Ce n’est pas théorique. Ça vient de l’observation des mêmes modes d’échec qui se répètent sur des dizaines d’engagements.
Définir les critères de succès avant le début du pilote
Ça semble évident. Presque personne ne le fait. Avant d’écrire une seule ligne de code, répondez à trois questions :
- Que doit faire cette fonctionnalité, précisément? Pas « résumer les données client ». Plutôt : « Générer un résumé de 3 à 5 phrases des 30 derniers jours d’activité client, incluant les changements de métriques clés et les événements notables, avec un taux d’erreur factuelle inférieur à 5 %. »
- Quel est le seuil de qualité minimum pour la production? Définissez-le avec des chiffres. Précision supérieure à 92 %. Latence inférieure à 2 secondes au p95. Score de satisfaction utilisateur supérieur à 4,2/5 en test. Si vous ne pouvez pas y mettre un chiffre, vous ne pouvez pas évaluer si le pilote a réussi.
- Quels sont les critères d’abandon? À quel moment arrêtez-vous l’expérience? Si après quatre semaines la précision est inférieure à 80 %, itérez-vous ou coupez-vous? Décider cela à l’avance empêche la mort lente d’un pilote qui ne fonctionne pas mais que personne ne veut annuler.
Écrivez-les. Mettez-les dans le brief du projet. Passez-les en revue avec la direction avant le début du pilote. Cette seule étape élimine le mode d’échec le plus courant : un pilote qui « fonctionne à peu près » et stagne dans les limbes parce que personne ne s’est entendu sur ce à quoi le succès ressemble.
Construire l’infrastructure d’évaluation en parallèle avec la fonctionnalité
L’évaluation n’est pas quelque chose qu’on ajoute après que la fonctionnalité fonctionne. On la construit en parallèle. Chaque fonctionnalité IA a besoin de trois choses dès le premier jour.
Un jeu de données de test. Organisez 200 à 500 exemples qui représentent vos vraies données de production. Incluez les cas limites. Incluez les entrées multilingues si votre produit les supporte. Incluez les données les plus désordonnées et incohérentes que vos clients produisent réellement. Ce jeu de données est le fondement de chaque décision qualité que vous prendrez.
L’évaluation automatisée. Construisez un script qui exécute votre fonctionnalité sur le jeu de données de test et produit un score de qualité. Pour les fonctionnalités génératives, cela peut signifier utiliser un patron LLM-as-judge où un modèle séparé note les sorties par rapport aux réponses de référence. Pour les fonctionnalités de classification, ce sont les métriques standard de précision/rappel. Le but : n’importe quel ingénieur peut exécuter ce script à tout moment et obtenir une réponse claire sur l’amélioration ou la dégradation de la qualité.
Une base de régression. Enregistrez les scores de votre implémentation actuelle. Chaque changement aux prompts, modèles ou logique de traitement est évalué par rapport à cette base. Si le changement n’améliore pas le score, il ne sort pas.
Cette infrastructure ajoute environ une semaine au calendrier du pilote. Elle économise des mois d’ambiguïté par la suite.
Traiter les fonctionnalités IA comme tout autre projet d’ingénierie
L’erreur organisationnelle la plus courante des scale-ups avec l’IA : la traiter comme un projet de recherche plutôt qu’un projet d’ingénierie. Les projets de recherche ont des échéances ouvertes et des livrables incertains. Les projets d’ingénierie ont des spécifications, de la revue de code, des tests, du CI/CD et des pipelines de déploiement.
Les fonctionnalités IA méritent la même rigueur que tout le reste dans votre produit.
Revue de code. Chaque changement de prompt, chaque modification de pipeline, chaque remplacement de modèle passe par la revue de code. C’est ainsi que les connaissances de l’équipe se propagent. C’est aussi ainsi qu’on attrape le « contournement temporaire » de l’ingénieur ML avant qu’il ne devienne de la dette technique permanente.
Tests. Tests unitaires pour la logique de traitement des données. Tests d’intégration pour le pipeline complet. La suite d’évaluation automatisée comme porte de validation en CI. Si le score d’évaluation descend sous la base de référence, la PR ne fusionne pas.
Surveillance. Journalisez les entrées et sorties (avec les contrôles de confidentialité appropriés). Suivez la latence, les taux d’erreur et les métriques de qualité dans votre pile d’observabilité existante. Configurez des alertes pour les anomalies. Traitez une baisse de 10 % de la qualité des sorties IA de la même façon qu’une augmentation de 10 % du taux d’erreur API.
Déploiement incrémental. Feature flags. Déploiements par pourcentage. Tests A/B contre la version non-IA si elle existe. Ne basculez pas le commutateur pour 15 000 clients le premier jour. Déployez pour 5 % des utilisateurs, surveillez pendant une semaine, puis élargissez.
Rien de tout cela n’est spécifique à l’IA. C’est la pratique standard d’ingénierie logicielle. L’erreur est de traiter les fonctionnalités IA comme exemptées des processus qui maintiennent la fiabilité de tout le reste.
Doter correctement le travail en personnel
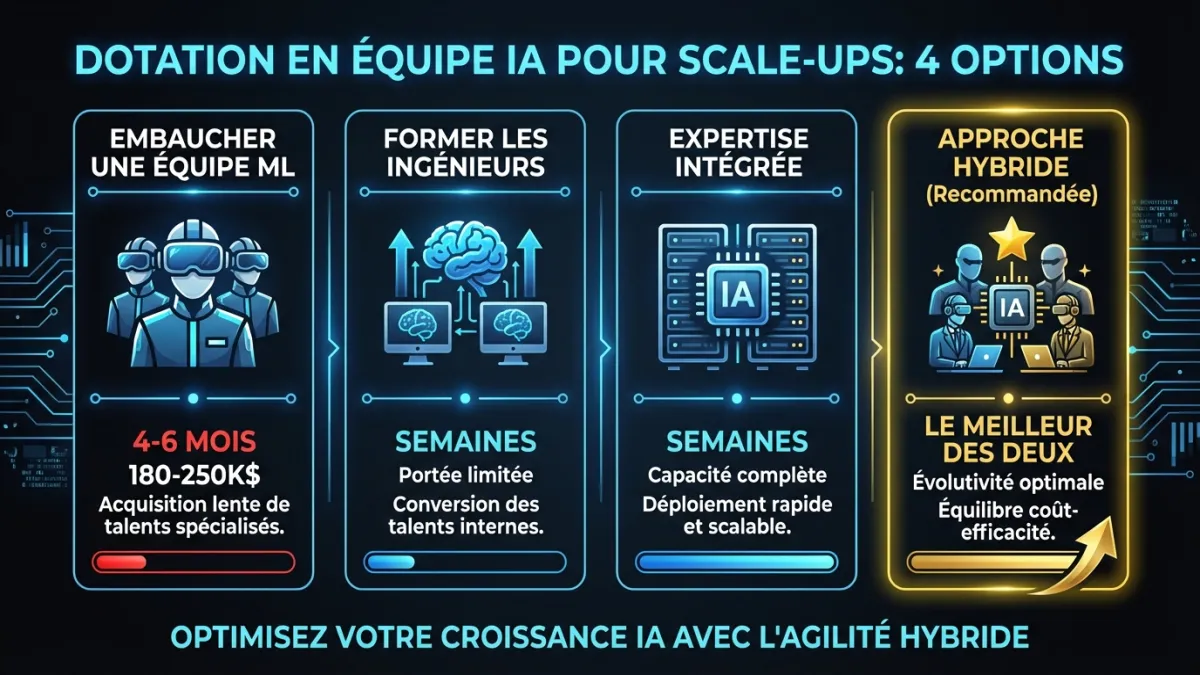
C’est là que la plupart des scale-ups font face au compromis le plus difficile. Vous avez besoin de quelqu’un avec une expertise ML pour construire la fonctionnalité. Vos options :
Option A : Embaucher une équipe ML. Délai : 4 à 6 mois pour pourvoir le premier poste, encore 3 à 6 mois avant qu’ils soient productifs dans votre codebase. Coût : 180-250K$ par ingénieur ML senior, et il en faut au moins deux pour une capacité significative. Le bon jeu à long terme si l’IA est centrale dans votre stratégie produit. Le mauvais jeu si vous avez besoin de fonctionnalités IA en production ce trimestre.
Option B : Monter en compétence les ingénieurs existants. Vos ingénieurs backend seniors peuvent apprendre à construire des fonctionnalités basées sur les LLM. La courbe d’apprentissage pour le prompt engineering et l’intégration API se mesure en semaines, pas en mois. Mais l’infrastructure d’évaluation, la sélection de modèles et les patrons ML de production prennent plus de temps. Ça fonctionne pour les fonctionnalités simples. Ça ne tient plus pour tout ce qui nécessite de l’entraînement personnalisé, du fine-tuning ou de l’orchestration complexe.
Option C : Intégrer de l’expertise externe. Faites appel à des ingénieurs IA seniors qui travaillent au sein de votre équipe : même codebase, mêmes standups, mêmes outils. Ils construisent la fonctionnalité avec vos ingénieurs, et votre équipe absorbe les connaissances par le jumelage et la revue de code. Délai : des semaines, pas des mois. Vos ingénieurs apprennent en construisant aux côtés de quelqu’un qui l’a déjà fait.
Option D : Hybride. Commencez avec de l’expertise intégrée pour livrer les premières fonctionnalités et former l’équipe. Embauchez des ingénieurs ML permanents en parallèle. Quand la recrue arrive, elle rejoint une équipe qui a déjà des fonctionnalités IA en production, une infrastructure d’évaluation et des patrons établis. Son temps d’intégration passe de 6 mois à 6 semaines parce que les fondations existent déjà.
Pour la plupart des entreprises Série A/B avec lesquelles nous travaillons, l’Option D produit les meilleurs résultats. Vous mettez des fonctionnalités IA en production rapidement, votre équipe développe une vraie capacité, et votre future recrue ML hérite d’un système fonctionnel au lieu de partir de zéro. Notre équipe de conseil en IA peut vous aider à déterminer quelle approche convient à votre situation spécifique.
Ce que signifie vraiment « prêt pour l’IA » à ce stade
Il y a un mythe persistant selon lequel vous avez besoin d’une plateforme de données, d’un feature store, d’un registre de modèles et d’un cluster GPU avant de pouvoir livrer des fonctionnalités IA. C’est de la pensée d’entreprise appliquée à la réalité des scale-ups. Ça mène à des projets d’infrastructure de 6 mois qui retardent le vrai travail produit.
Au stade de la scale-up, « prêt pour l’IA » signifie cinq choses.
Vos données sont accessibles via API ou requêtes en base de données. Pas dans des exports CSV. Pas dans un entrepôt de données que seule l’équipe analytique peut interroger. Les données de votre application doivent être interrogeables par le code de votre fonctionnalité IA en temps réel. Si votre produit utilise PostgreSQL, c’est probablement suffisant. Si des données critiques sont enfermées dans des systèmes tiers sans accès API, c’est un bloqueur.
Vous avez un pipeline de déploiement qui supporte les changements de configuration. Les fonctionnalités IA nécessitent des itérations fréquentes. Les changements de prompts, les changements de version de modèle et les ajustements de seuils doivent être déployables sans un cycle de release complet. Les feature flags et les variables d’environnement font beaucoup ici.
Votre pile d’observabilité peut gérer les données non structurées. Vous devez journaliser les entrées et sorties IA à côté de vos logs applicatifs existants. La plupart des outils d’observabilité modernes le supportent. Si vous utilisez déjà Datadog, Grafana ou similaire, vous pouvez étendre ce que vous avez.
Vous avez un environnement de staging avec des données réalistes. Les fonctionnalités IA se comportent différemment sur des données synthétiques par rapport aux données de production. Votre environnement de staging a besoin d’un jeu de données représentatif. Pas une copie complète de production. Un échantillon de 10 % avec des données personnelles correctement anonymisées suffit pour la plupart du travail d’évaluation.
Votre équipe a des connaissances de base en prompt engineering. Au moins deux ingénieurs devraient comprendre comment structurer des prompts, gérer les fenêtres de contexte et évaluer les sorties de modèles. Quelques jours d’apprentissage, pas un programme de certification. Notre feuille de route stratégie produit IA couvre les concepts fondamentaux.
C’est tout. Pas de cluster Kubernetes pour le serving de modèles. Pas d’infrastructure d’entraînement personnalisée. Pas de data lake. Tout cela viendra plus tard, si jamais ça vient. La plupart des fonctionnalités IA des scale-ups tournent sur des appels API à des modèles de fondation avec une bonne ingénierie autour.
Échéanciers réalistes pour une entreprise de 100 personnes
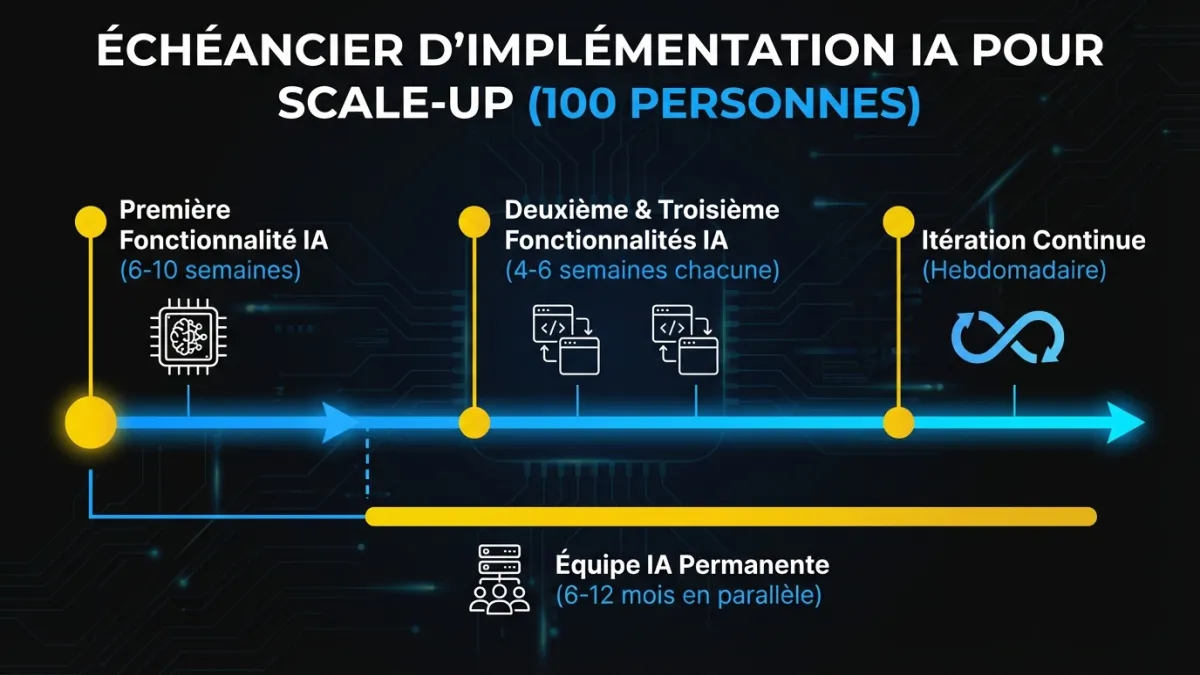
Voici ce que nous avons observé sur des dizaines d’implémentations IA dans des scale-ups. Ces estimations supposent une équipe qui suit le cadre ci-dessus et a accès à une expertise ML, qu’elle soit interne ou intégrée.
Première fonctionnalité IA en production : 6 à 10 semaines à partir du lancement. Deux semaines pour le cadrage et les critères de succès. Deux semaines pour le pilote avec l’infrastructure d’évaluation construite en parallèle. Deux à quatre semaines pour le durcissement production, la surveillance et le déploiement progressif. La première prend le plus de temps parce que vous construisez les patrons d’évaluation et de déploiement de zéro.
Deuxième et troisième fonctionnalités : 4 à 6 semaines chacune. L’infrastructure existe. L’équipe connaît les patrons. Le processus de déploiement est établi. Chaque fonctionnalité suivante avance plus vite parce que vous réutilisez les fondations.
Itération continue : Hebdomadaire ou bihebdomadaire. Une fois qu’une fonctionnalité est en production avec une infrastructure d’évaluation appropriée, les améliorations deviennent du travail d’ingénierie de routine. Changez une version de modèle, exécutez la suite d’évaluation, déployez si les scores s’améliorent.
Construction d’une équipe IA permanente : 6 à 12 mois en parallèle. Commencez le recrutement après que la première fonctionnalité soit en production. Les candidats sont plus intéressés à rejoindre une équipe qui a déjà des fonctionnalités IA en production qu’une qui « prévoit de faire de l’IA ». Votre expertise intégrée reste jusqu’à ce que l’équipe permanente soit autonome.
Le plus gros gouffre de temps n’est presque jamais le travail IA lui-même. C’est organisationnel : aligner la direction sur les priorités, libérer de la capacité d’ingénierie et prendre la décision de traiter les fonctionnalités IA comme de vrais engagements produit plutôt que des expériences secondaires.
Le coût de rester dans le purgatoire des pilotes
Les scale-ups qui ne comblent pas l’écart pilote-production ne font pas du surplace. Elles reculent. Les concurrents livrent des fonctionnalités IA qui améliorent l’expérience utilisateur, réduisent le taux de désabonnement et créent des coûts de changement. Chaque trimestre passé dans le purgatoire des pilotes creuse cet écart.
La sortie est directe. Définissez à quoi ressemble le succès avant de commencer à construire. Investissez dans l’infrastructure d’évaluation dès le premier jour. Appliquez la même discipline d’ingénierie aux fonctionnalités IA que vous appliquez à tout le reste. Dotez le travail avec des personnes qui ont déjà mis de l’IA en production, que ce soit une nouvelle recrue ou une équipe intégrée qui travaille dans votre codebase.
Les entreprises qui avancent le plus vite ne sont pas celles avec le plus de docteurs en ML. Ce sont celles qui traitent l’IA comme un problème d’ingénierie et qui développent la capacité de la livrer comme tout le reste.
Prêt à faire passer vos pilotes IA en production? Discutez avec notre équipe de l’intégration d’ingénieurs IA seniors directement dans votre organisation d’ingénierie.