A Series B company with 120 employees, 40 engineers, and 15,000 paying customers has a specific AI problem. They have enough data and enough customers to make AI genuinely valuable. They also have zero ML engineers, a packed roadmap, and a CEO who just told the board that AI features are coming in Q3.
This is the scale-up AI trap. You’re big enough that AI matters, small enough that you can’t staff it, and busy enough that every AI experiment competes with features customers are already paying for.
Most of these companies end up in pilot purgatory. Someone builds a prototype in a Jupyter notebook. It demos well. Leadership gets excited. Then nothing ships. The distance between a working prototype and a production feature is longer than anyone estimated.
Why Scale-Ups Specifically Get Stuck
Startups have a simpler version of this problem. Fewer users, simpler infrastructure, founders who can pivot the entire roadmap toward AI on a whim. Enterprises have it easier too. They can hire a 10-person ML team, spin up a dedicated AI org, and wait 18 months for results.
Scale-ups get neither luxury. Three constraints make AI execution uniquely difficult at this stage.
Constraint 1: The talent gap is real, but the hiring timeline doesn’t fit. Hiring a senior ML engineer takes 4-6 months. Finding one who also understands your product domain takes longer. By the time you’ve filled the role, the board has already asked twice why the AI features aren’t live.
Constraint 2: Every sprint carries an opportunity cost. A 40-person engineering team at a scale-up isn’t sitting around looking for projects. The backlog is full of customer requests, infrastructure work, and features tied to revenue targets. Pulling two engineers off the roadmap for an AI experiment means something else doesn’t ship. That trade-off only works if the AI work actually reaches production.
Constraint 3: Prototypes are dangerously convincing. A competent engineer can build an AI feature that works in a demo in about two weeks. GPT-4 or Claude will generate reasonable outputs for most text-based tasks. The prototype looks impressive in a Slack thread. Leadership sees it and assumes it’s 80% done. In reality, it’s 20% done. The remaining 80% is the part nobody planned for.
What’s Actually in the Pilot-to-Production Gap
The gap between “this works in a demo” and “this works in production” isn’t a single problem. It’s five distinct engineering challenges that most scale-ups haven’t scoped.
Evaluation infrastructure. How do you know the AI feature is working well? Not anecdotally. Quantitatively. You need metrics that define success, a way to measure them automatically, and baselines to compare against. For a text generation feature, that might mean building a labeled test set of 500+ examples, defining quality rubrics, and running automated evals on every model change. Most pilots have none of this. The team “eyeballs” outputs and says they look good.
Data pipeline reliability. The prototype pulls data from a staging database and processes it in a notebook. Production requires a pipeline that handles missing fields, schema changes, rate limits, and the inevitable moment when a customer has 10x more data than your test cases assumed. A recommendation feature that works on 1,000 records and breaks at 50,000 is not a production feature.
Edge case handling. AI features fail in ways that traditional software doesn’t. A classification model trained on English data produces garbage when a customer inputs French. A summarization feature hallucinates a number that looks plausible but is wrong. A search feature returns confidential data from one tenant to another because the embedding index wasn’t properly scoped. These aren’t hypothetical scenarios. They’re the bugs that show up in the first week after launch.
Monitoring and observability. Traditional software either works or throws an error. AI features degrade silently. Response quality drops because the underlying model was updated. Latency increases because prompt length grew. Accuracy decreases on a specific customer segment because their data distribution shifted. Without monitoring that tracks output quality over time, you won’t know the feature is failing until customers tell you.
Team knowledge transfer. The engineer who built the prototype understands the prompt structure, the model selection rationale, and the workarounds they implemented. None of that is documented. When that engineer goes on vacation or moves to another project, the feature becomes a black box nobody can debug or improve.
Each of these challenges is a week or more of engineering work. Added together, they explain why the jump from pilot to production typically takes 3-5x longer than the pilot itself.
A Practical Framework for Getting AI to Production
This is the AI implementation strategy we apply when working with scale-up engineering teams. It’s not theoretical. It comes from watching the same failure modes repeat across dozens of engagements.
Define Success Criteria Before the Pilot Starts
This sounds obvious. Almost nobody does it. Before writing a single line of code, answer three questions:
- What does this feature need to do, specifically? Not “summarize customer data.” Instead: “Generate a 3-5 sentence summary of the last 30 days of customer activity, including key metrics changes and notable events, with less than 5% factual error rate.”
- What’s the minimum quality threshold for production? Define this with numbers. Accuracy above 92%. Latency under 2 seconds at p95. User satisfaction score above 4.2/5 in testing. If you can’t put a number on it, you can’t evaluate whether the pilot succeeded.
- What’s the kill criteria? At what point do you stop the experiment? If after four weeks the accuracy is below 80%, do you iterate or cut? Deciding this upfront prevents the slow death of a pilot that isn’t working but nobody wants to cancel.
Write these down. Put them in the project brief. Review them with leadership before the pilot begins. This single step eliminates the most common failure mode: a pilot that “kinda works” and sits in limbo because nobody agreed on what success looks like.
Build Evaluation Infrastructure Alongside the Feature
Evaluation isn’t something you add after the feature works. You build it in parallel. Every AI feature needs three things from day one.
A test dataset. Curate 200-500 examples that represent your actual production data. Include edge cases. Include multilingual inputs if your product supports them. Include the messiest, most inconsistent data your customers actually produce. This dataset is the foundation of every quality decision you’ll make.
Automated evaluation. Build a script that runs your feature against the test dataset and produces a quality score. For generative features, this might mean using an LLM-as-judge pattern where a separate model grades the outputs against reference answers. For classification features, it’s standard precision/recall metrics. The point: any engineer can run this script at any time and get a clear answer about whether quality improved or degraded.
A regression baseline. Record the scores from your current implementation. Every change to prompts, models, or processing logic gets evaluated against this baseline. If the change doesn’t improve the score, it doesn’t ship.
This infrastructure adds about a week to the pilot timeline. It saves months of ambiguity later.
Treat AI Features Like Any Other Engineering Project
The most common organizational mistake scale-ups make with AI: treating it as a research project instead of an engineering project. Research projects have open-ended timelines and uncertain deliverables. Engineering projects have specifications, code review, testing, CI/CD, and deployment pipelines.
AI features deserve the same rigor as everything else in your product.
Code review. Every prompt change, every pipeline modification, every model swap goes through code review. This is how team knowledge spreads. It’s also how you catch the ML engineer’s “temporary workaround” before it becomes permanent tech debt.
Testing. Unit tests for data processing logic. Integration tests for the full pipeline. The automated evaluation suite as a gate in CI. If the eval score drops below the baseline, the PR doesn’t merge.
Monitoring. Log inputs and outputs (with appropriate privacy controls). Track latency, error rates, and quality metrics in your existing observability stack. Set alerts for anomalies. Treat a 10% drop in AI output quality the same way you’d treat a 10% increase in API error rate.
Incremental rollout. Feature flags. Percentage-based rollouts. A/B testing against the non-AI version if one exists. Don’t flip the switch for 15,000 customers on day one. Roll out to 5% of users, monitor for a week, then expand.
None of this is specific to AI. It’s standard software engineering practice. The mistake is treating AI features as exempt from the processes that keep everything else reliable.
Staff the Work Correctly
This is where most scale-ups face the hardest trade-off. You need someone with ML expertise to build the feature. Your options:
Option A: Hire an ML team. Timeline: 4-6 months to fill the first role, another 3-6 months before they’re productive in your codebase. Cost: $180-250K per senior ML engineer, and you need at least two for meaningful capability. The right long-term play if AI is central to your product strategy. The wrong play if you need AI features in production this quarter.
Option B: Upskill existing engineers. Your senior backend engineers can learn to build LLM-based features. The learning curve for prompt engineering and API integration is weeks, not months. But evaluation infrastructure, model selection, and production ML patterns take longer. This works for straightforward features. It breaks down for anything requiring custom training, fine-tuning, or complex orchestration.
Option C: Embed external expertise. Bring in senior AI engineers who work inside your team: same codebase, same standups, same tools. They build the feature alongside your engineers, and your team absorbs the knowledge through pairing and code review. Timeline: weeks, not months. Your engineers learn by building alongside someone who’s done it before.
Option D: Hybrid. Start with embedded expertise to ship the first features and train the team. Hire permanent ML engineers in parallel. When the hire starts, they join a team that already has production AI features, evaluation infrastructure, and established patterns. Their ramp time drops from 6 months to 6 weeks because the foundation already exists.
For most Series A/B companies we work with, Option D produces the best outcomes. You get AI features into production fast, your team builds real capability, and your eventual ML hire inherits a working system instead of starting from scratch. Our AI advisory team can help you map which approach fits your specific situation.
What “AI-Ready” Infrastructure Actually Means at This Stage
There’s a persistent myth that you need a data platform, a feature store, a model registry, and a GPU cluster before you can ship AI features. That’s enterprise thinking applied to scale-up reality. It leads to 6-month infrastructure projects that delay actual product work.
At the scale-up stage, “AI-ready” means five things.
Your data is accessible via API or database queries. Not in CSV exports. Not in a data warehouse only the analytics team can query. Your application data needs to be queryable by your AI feature code in real time. If your product uses PostgreSQL, that’s probably fine. If critical data is locked in third-party systems with no API access, that’s a blocker.
You have a deployment pipeline that supports configuration changes. AI features need frequent iteration. Prompt changes, model version swaps, and threshold adjustments should be deployable without a full release cycle. Feature flags and environment variables go a long way here.
Your observability stack can handle unstructured data. You need to log AI inputs and outputs alongside your existing application logs. Most modern observability tools support this. If you’re using Datadog, Grafana, or similar, you can extend what you have.
You have a staging environment with realistic data. AI features behave differently on synthetic data versus production data. Your staging environment needs a representative dataset. Not a full production copy. A 10% sample with properly anonymized PII is enough for most evaluation work.
Your team has basic prompt engineering knowledge. At least two engineers should understand how to structure prompts, handle context windows, and evaluate model outputs. A few days of learning, not a certification program. Our AI product strategy roadmap covers the foundational concepts.
That’s it. No Kubernetes cluster for model serving. No custom training infrastructure. No data lake. Those come later, if they come at all. Most scale-up AI features run on API calls to foundation models with good engineering around them.
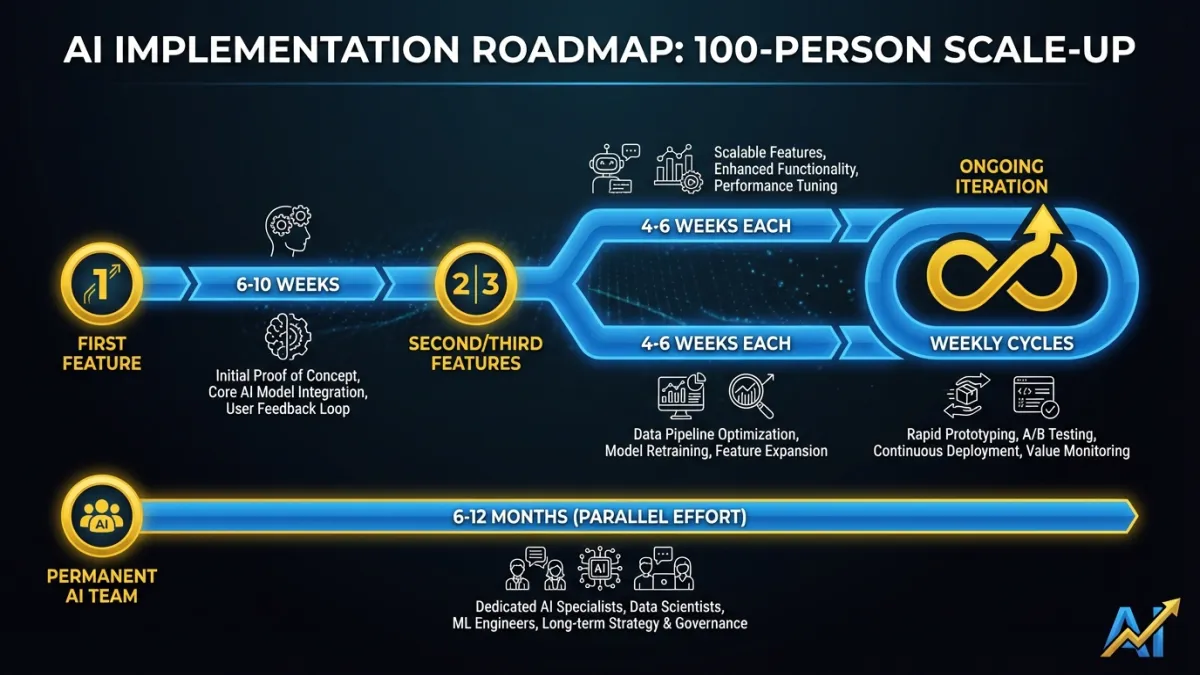
Realistic Timelines for a 100-Person Company
Here’s what we’ve seen across dozens of scale-up AI implementations. These assume a team that follows the framework above and has access to ML expertise, whether internal or embedded.
First production AI feature: 6-10 weeks from kickoff. Two weeks for scoping and success criteria. Two weeks for the pilot with evaluation infrastructure built in parallel. Two to four weeks for production hardening, monitoring, and staged rollout. The first one takes the longest because you’re building the evaluation and deployment patterns from scratch.
Second and third features: 4-6 weeks each. The infrastructure exists. The team knows the patterns. The deployment process is established. Each subsequent feature moves faster because you’re reusing the foundation.
Ongoing iteration: Weekly or biweekly. Once a feature is in production with proper evaluation infrastructure, improvements become routine engineering work. Swap a model version, run the eval suite, deploy if scores improve.
Building a permanent AI team: 6-12 months in parallel. Start hiring after the first feature ships. Candidates are more interested in joining a team that already has production AI features than one that’s “planning to do AI.” Your embedded expertise stays until the permanent team is self-sufficient.
The biggest time sink is almost never the AI work itself. It’s organizational: getting leadership aligned on priorities, freeing up engineering capacity, and making the decision to treat AI features as real product commitments instead of side experiments.
The Cost of Staying in Pilot Purgatory
Scale-ups that don’t close the pilot-to-production gap aren’t standing still. They’re falling behind. Competitors are shipping AI features that improve user experience, reduce churn, and create switching costs. Every quarter spent in pilot purgatory widens that gap.
The path out is straightforward. Define what success looks like before you start building. Invest in evaluation infrastructure from day one. Apply the same engineering discipline to AI features that you apply to everything else. Staff the work with people who’ve shipped AI to production before, whether that’s a new hire or an embedded team that works inside your codebase.
The companies that move fastest aren’t the ones with the most ML PhDs. They’re the ones that treat AI as an engineering problem and build the muscle to ship it like everything else.
Ready to move your AI pilots into production? Talk to our team about embedding senior AI engineers directly into your engineering org.